Write-heavy Systems

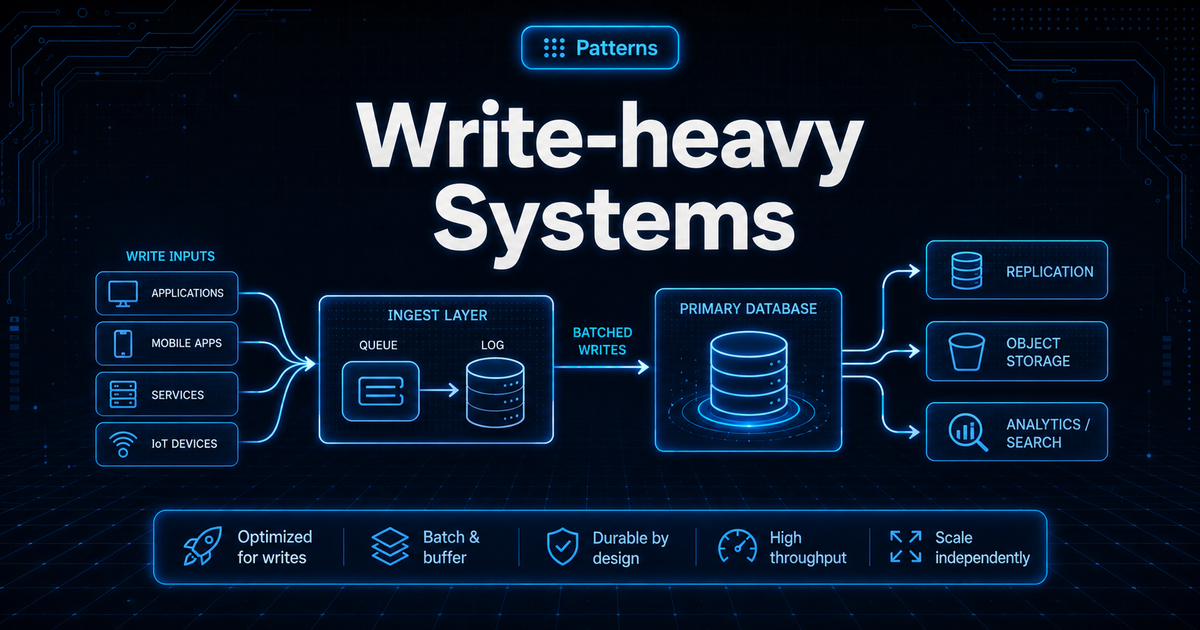
A write-heavy system receives many writes, events, or updates.
In interviews, the main challenge is protecting the system from overload while keeping writes durable and correct.What it means
A system is write-heavy when new data arrives very frequently.
Examples:
- logging system
- metrics platform
- click analytics
- chat messages
- location updates
- payment events
- IoT events
- view count tracking
In these systems, the write path matters more than the read path.
The main design goal
For write-heavy systems, ask:
- Can we accept eventual consistency?
- Can writes be batched?
- Can work be asynchronous?
- Do we need ordering?
- Can we partition the write load?
- How do we handle retries and duplicates?
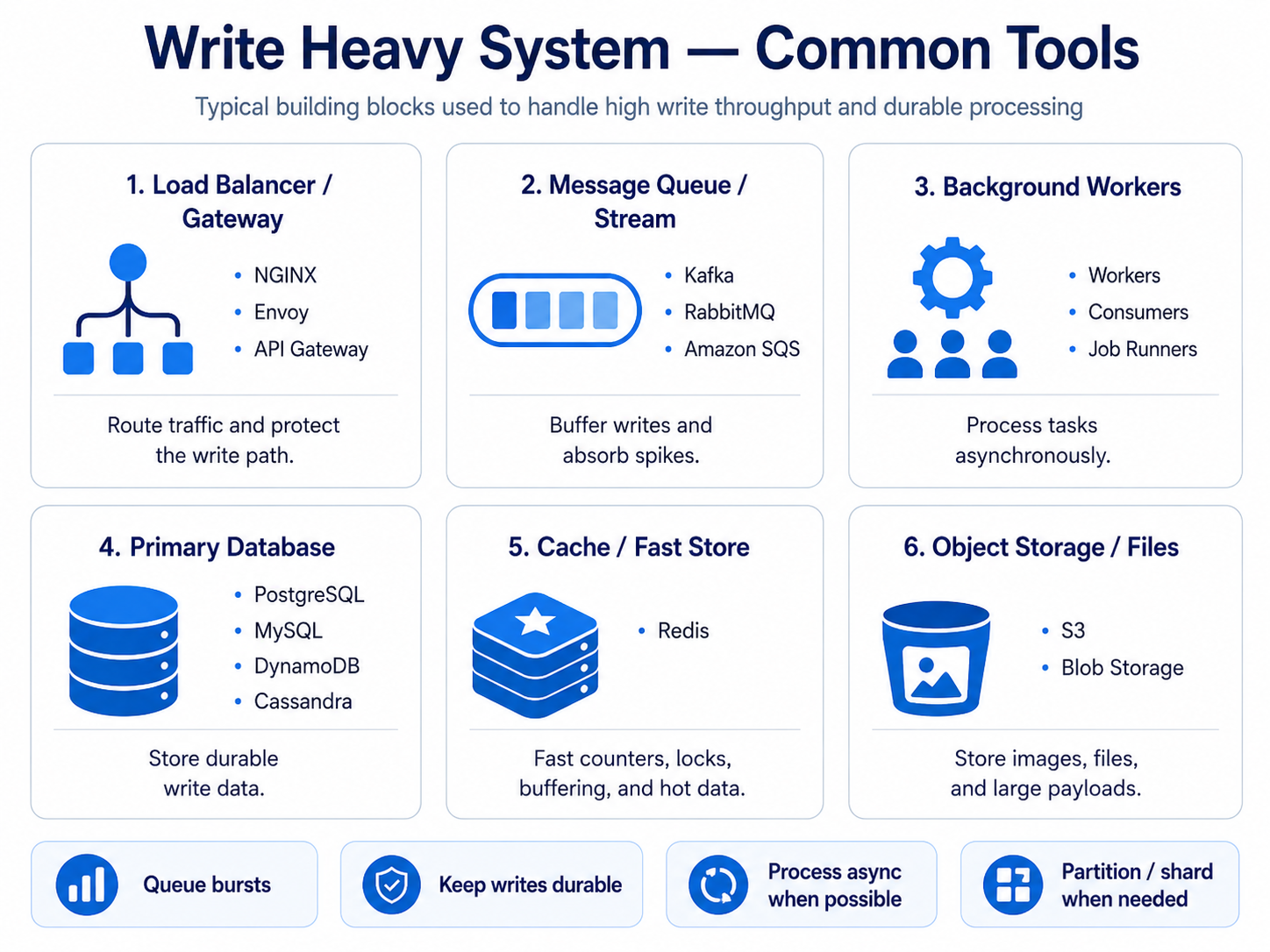
Common tools
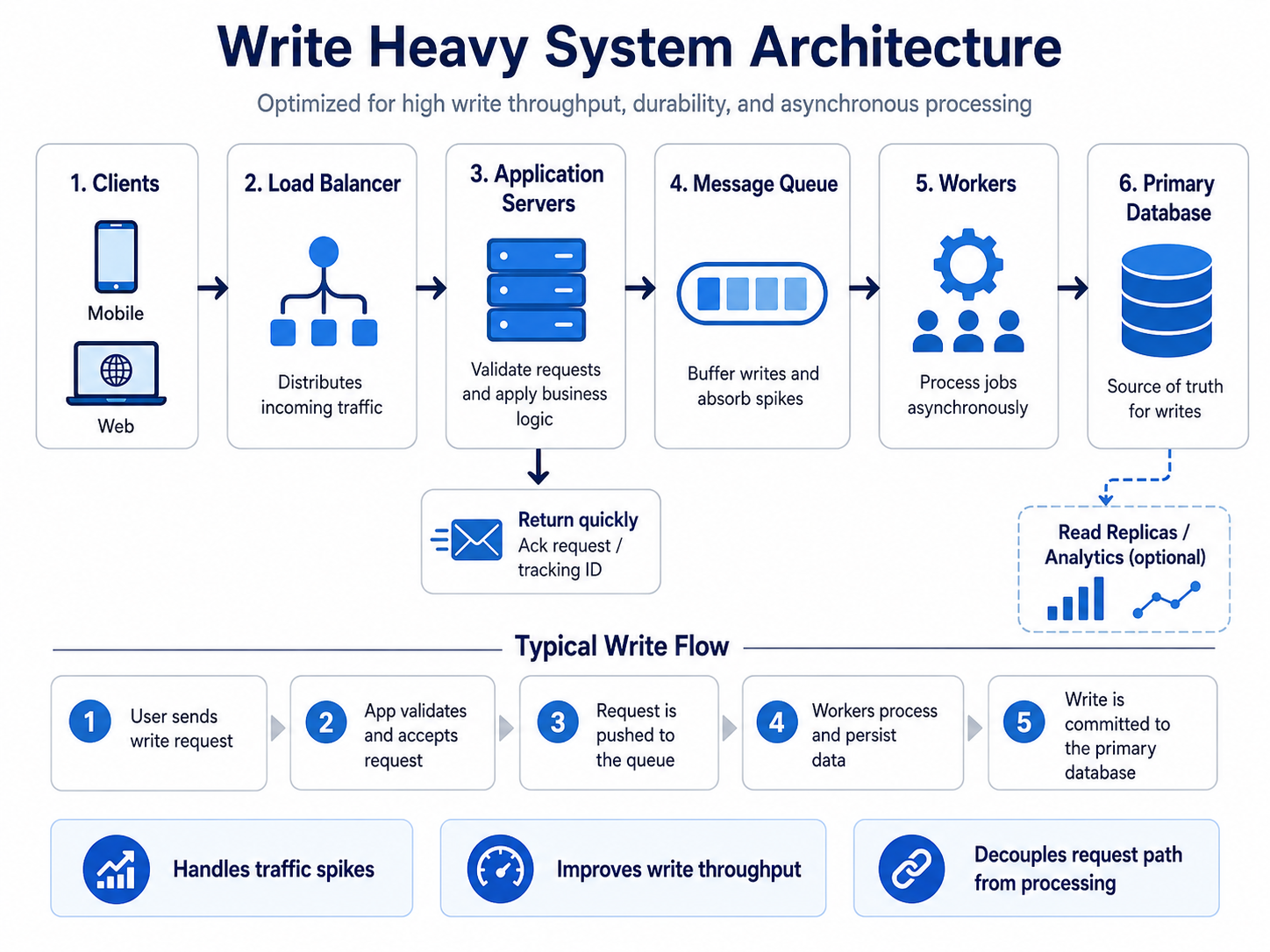
Example: click analytics
For URL shortener analytics, every redirect can produce a click event.
Bad design:
Redirect request → write analytics to DB → return redirect
This makes the user wait.
Better design:
Redirect request → publish click event → return redirect
→ analytics worker processes later
A good interview phrase:
I would keep the redirect path fast and publish click events to a queue. Analytics workers can process them asynchronously, so spikes in analytics traffic do not slow down redirects.
Common deep dives
Good write-heavy deep dives include:
- queue partitioning
- retry and dead letter queue
- idempotency
- batching
- backpressure
- consumer lag
- data retention
- exactly-once vs at-least-once processing
Consistency tradeoff
Many write-heavy systems are eventually consistent.
This is often acceptable for:
- analytics
- counters
- logs
- search indexing
- recommendations
But not acceptable for:
- payments
- inventory
- booking
- account balance
Common mistakes
- Writing every event synchronously to a relational database.
- Ignoring retries and duplicates.
- Forgetting backpressure.
- Not thinking about queue growth.
- Treating analytics like a strongly consistent transaction.
Final takeaway
For write-heavy systems, protect the critical path and process heavy work asynchronously.
A strong answer is:
The write volume is high, so I would buffer events through a queue, partition by a stable key, process with workers, and make consumers idempotent.