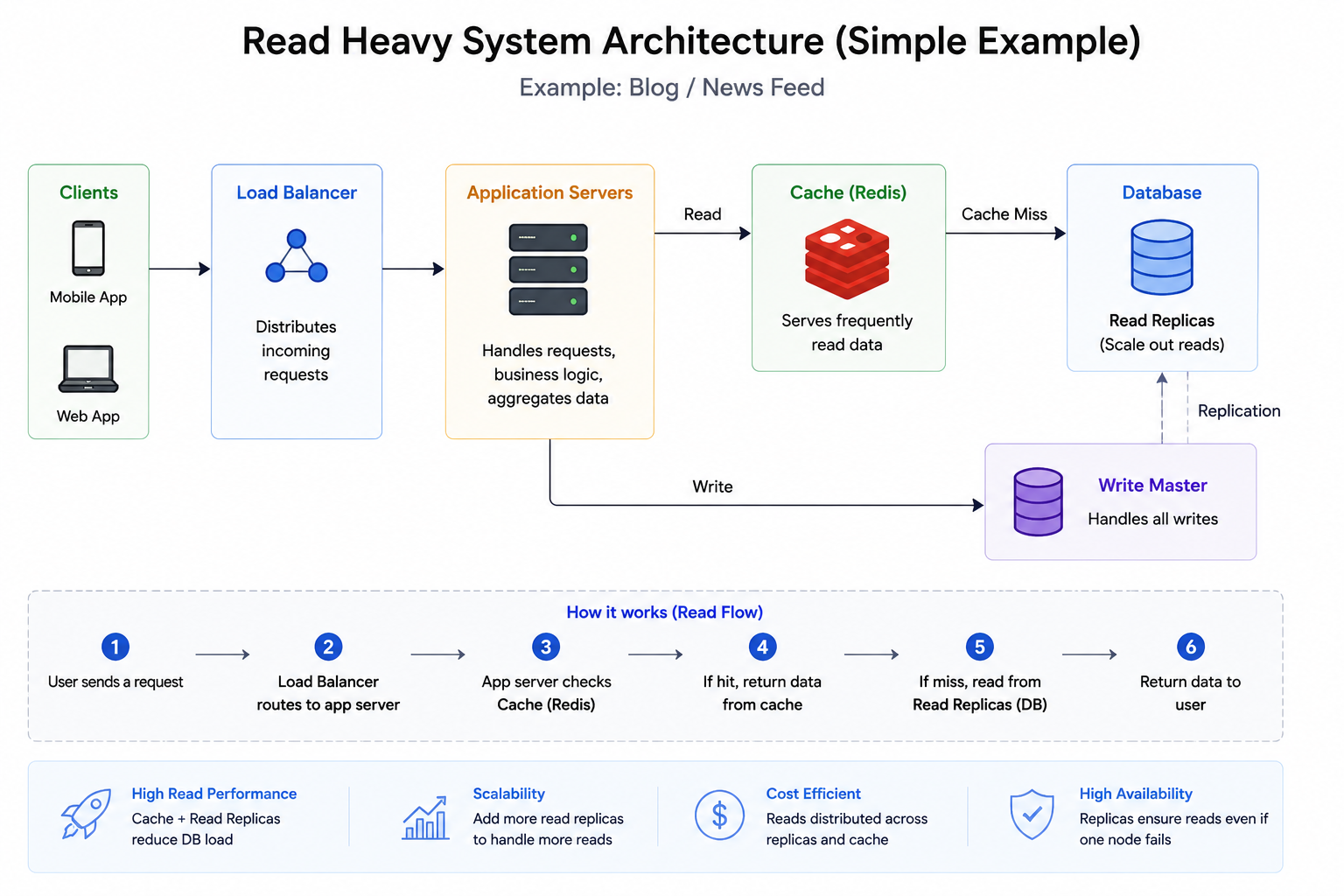
Read-heavy Systems

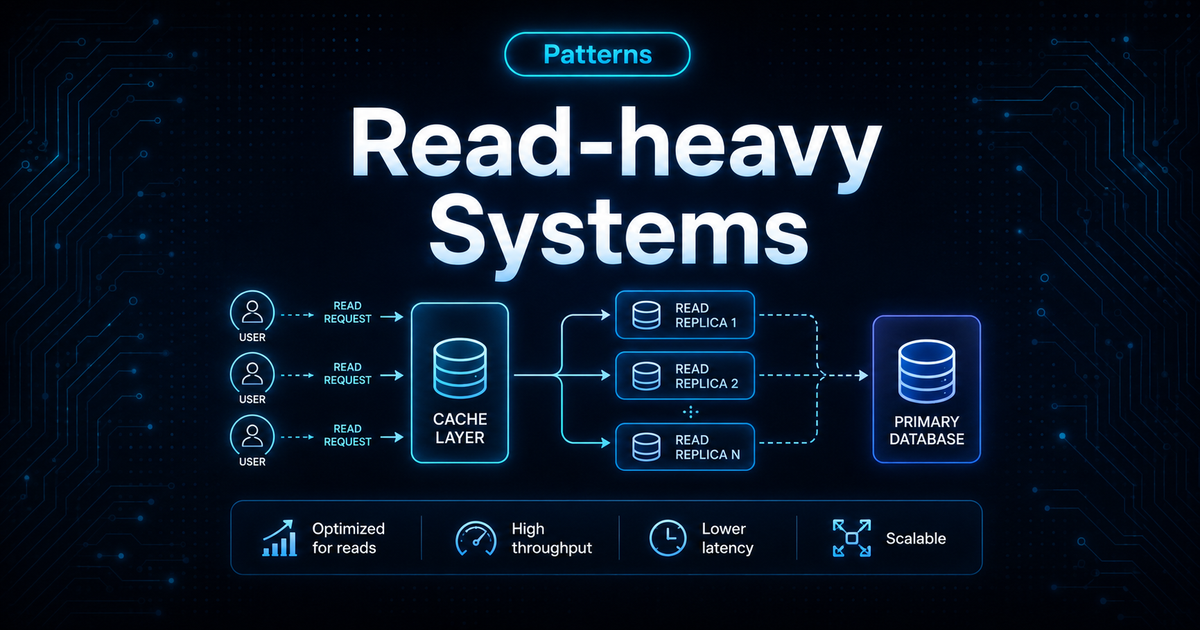
A read-heavy system has far more reads than writes.
In interviews, the main goal is to make the read path fast, cheap, and reliable.What it means
A system is read-heavy when users read data much more often than they create or update it.
Examples:
- URL shortener redirects
- product detail pages
- restaurant detail pages
- public profiles
- news feed reads
- video watch pages
A common ratio might be:
100 reads for every 1 write
The main design goal
For read-heavy systems, optimize the read path first.
Ask:
- What data is read most often?
- Can it be cached?
- Can it be served from CDN?
- Can we precompute it?
- Can read traffic avoid the primary database?
Common tools
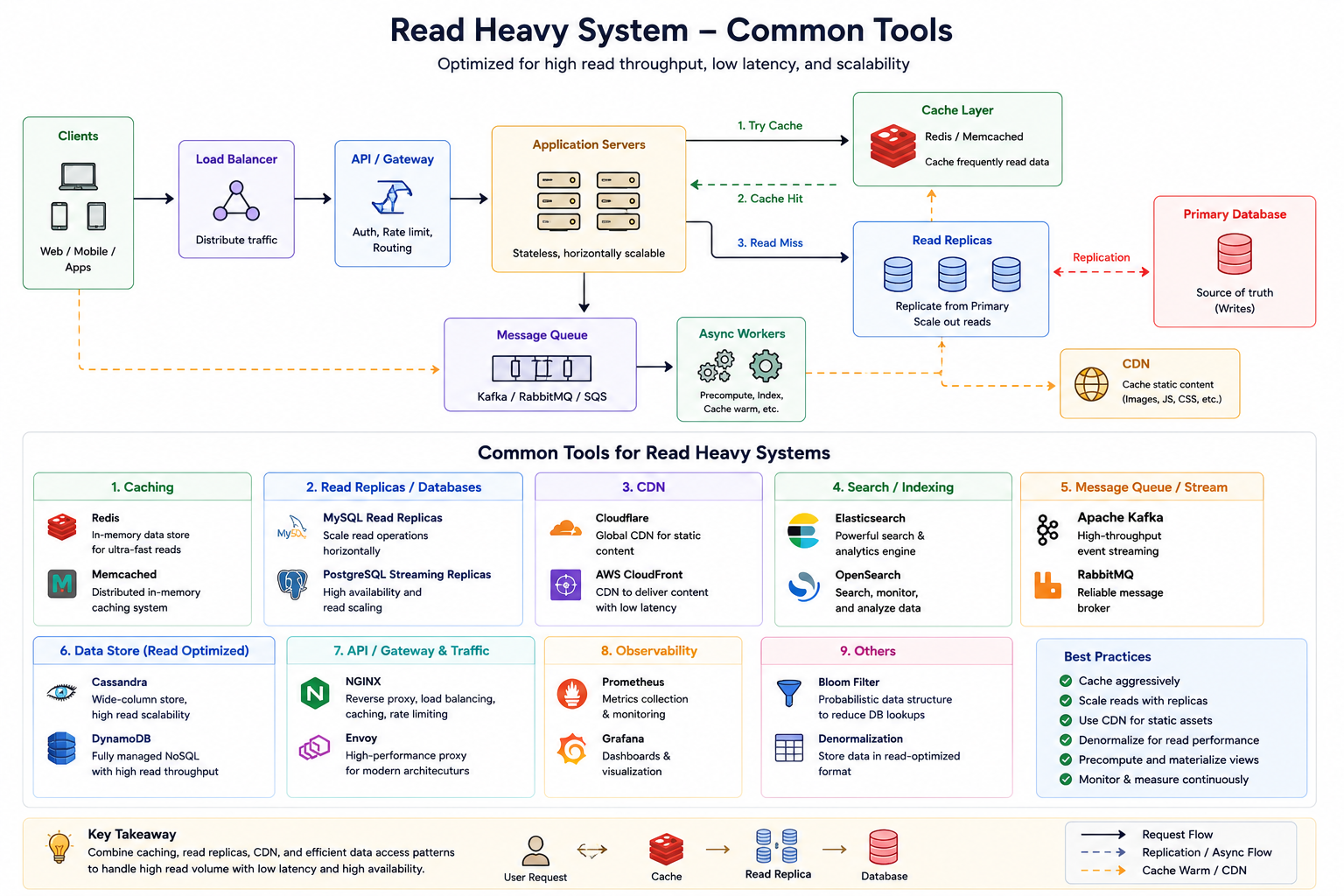
Common deep dives
Good read-heavy deep dives include:
- cache key and TTL
- cache invalidation
- hot key handling
- read replicas
- CDN for static content
- pagination
- precomputed data
- stale data tolerance
Common mistakes
- Adding cache without saying what is cached.
- Ignoring hot keys.
- Sending every read to the primary database.
- Forgetting cache invalidation.
- Overusing CDN for private or personalized data.
Final takeaway
For read-heavy systems, start with a simple design, then reduce pressure on the database.
A strong answer is:
The read path is the bottleneck, so I would use cache, CDN where possible, and read replicas. The tradeoff is stale data, so I would choose TTL and invalidation based on the freshness requirement.