Partitioning / Sharding Basics


Partitioning, or sharding, means splitting data across multiple machines.
In interviews, use it when one database can no longer hold all the data or handle all the traffic.The basic idea
A single database has limits.
It can run out of:
- storage,
- CPU,
- memory,
- read capacity,
- write capacity.
Sharding solves this by splitting data into smaller pieces.
Shard 1: users 1–1M
Shard 2: users 1M–2M
Shard 3: users 2M–3M
Each shard stores only part of the data.
Partitioning vs sharding
People often use these words in similar ways.
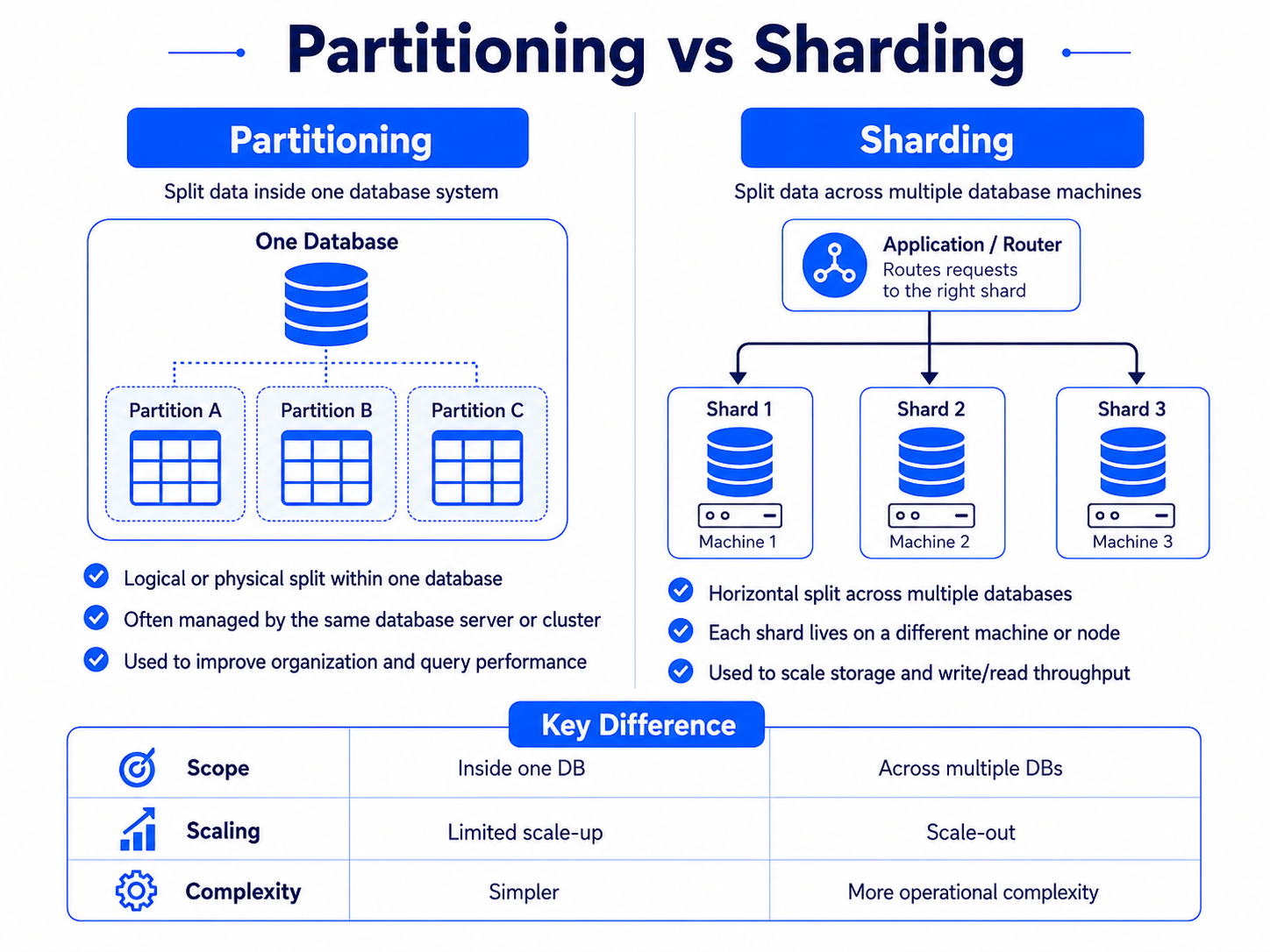
A simple way to think about it:
Partitioning = splitting data into parts
Sharding = placing those parts on different machines
In interviews, saying “sharding” is usually fine.
When to shard
Good interview signals:
- data is too large for one database,
- write traffic is too high,
- read traffic is too high even after cache and replicas,
- one table has billions of rows,
- storage keeps growing quickly,
- one machine is becoming a bottleneck.
Examples:
- URL mappings in a URL shortener,
- messages in a chat system,
- posts in a social network,
- orders in an e-commerce system,
- time-series logs,
- analytics events.
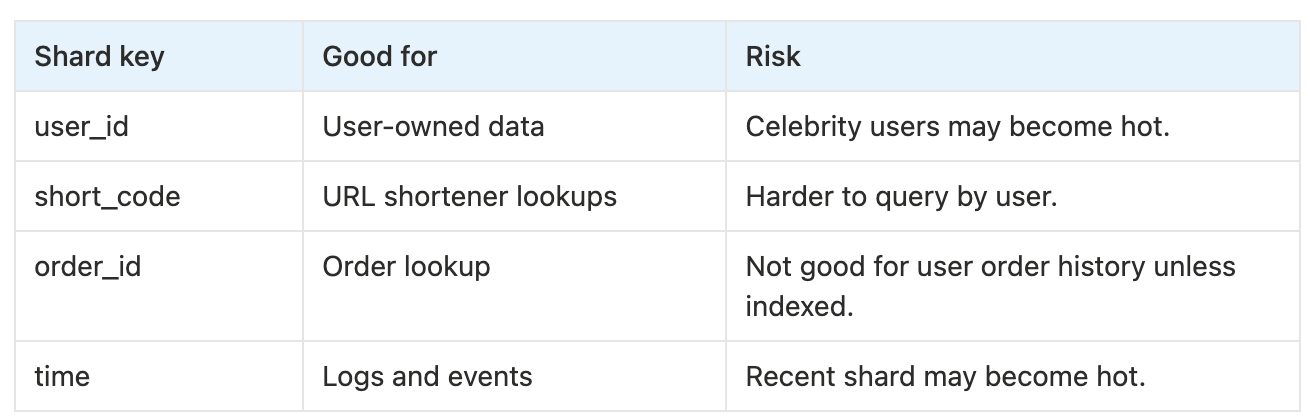
Common shard keys
The most important choice is the shard key.
The shard key decides where data goes.
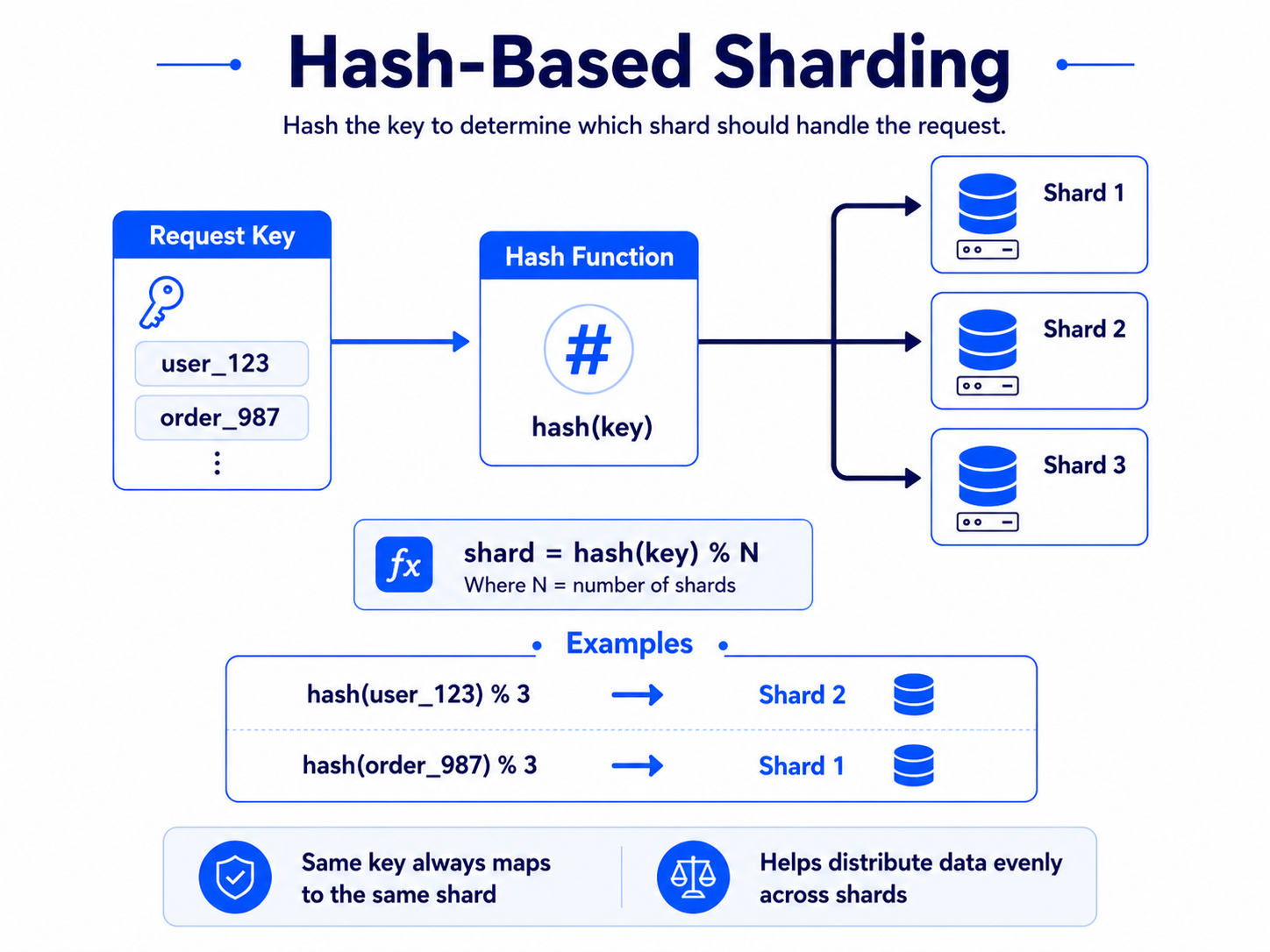
Hash-based sharding
Hash-based sharding spreads data evenly.
shard = hash(key) % number_of_shards
Good for:
- even distribution,
- simple key lookup,
- avoiding hot ranges.
Tradeoff:
- range queries become harder,
- adding shards may require data movement.
Range-based sharding
Range-based sharding splits data by value range.
Example:
A–F → Shard 1
G–M → Shard 2
N–Z → Shard 3
Or by time:
Jan data → Shard 1
Feb data → Shard 2
Mar data → Shard 3
Good for:
- range queries,
- time-based data,
- easier archival.
Tradeoff:
- hot ranges can happen,
- recent data may get too much traffic.
Cross-shard problems
Sharding makes some operations harder.
Examples:
- query all data for one user if data is sharded by something else,
- join data across shards,
- run global analytics,
- change shard count,
- handle hot shards.
A good answer should mention this.
Common mistakes
- Sharding too early.
- Choosing a shard key without explaining query patterns.
- Ignoring hot partitions.
- Forgetting cross-shard queries.
- Assuming sharding is free.
- Not explaining how requests find the right shard.
Final takeaway
Shard when one database is no longer enough.
A strong answer is:
I would choose the shard key based on the main access pattern. For URL shortener redirects, sharding by short code works well because each redirect becomes a single-shard lookup. The tradeoff is that other queries, like listing all URLs for a user, may need a separate index or different storage path.