Optimistic, Pessimistic & Distributed Locking


Concurrency control is about one simple question: what happens when two requests try to change the same data at the same time?
In interviews, this topic shows up in booking, inventory, payments, orders, auctions, and job scheduling.The problem
Many systems have shared resources.
Examples:
- two users try to book the same seat,
- two orders try to buy the last item in stock,
- two workers try to process the same job,
- one user clicks “pay” twice,
- many users bid on the same auction.
If we do nothing, the system may create duplicate orders, oversell inventory, or process the same job twice.
That is why we need concurrency control.
The three common tools
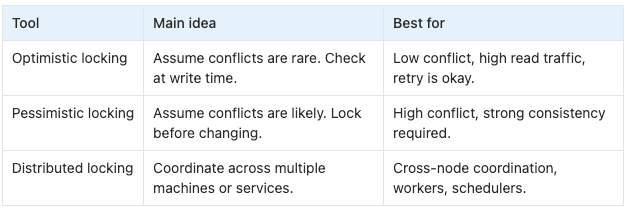
Optimistic locking
Optimistic locking assumes conflicts are not common.
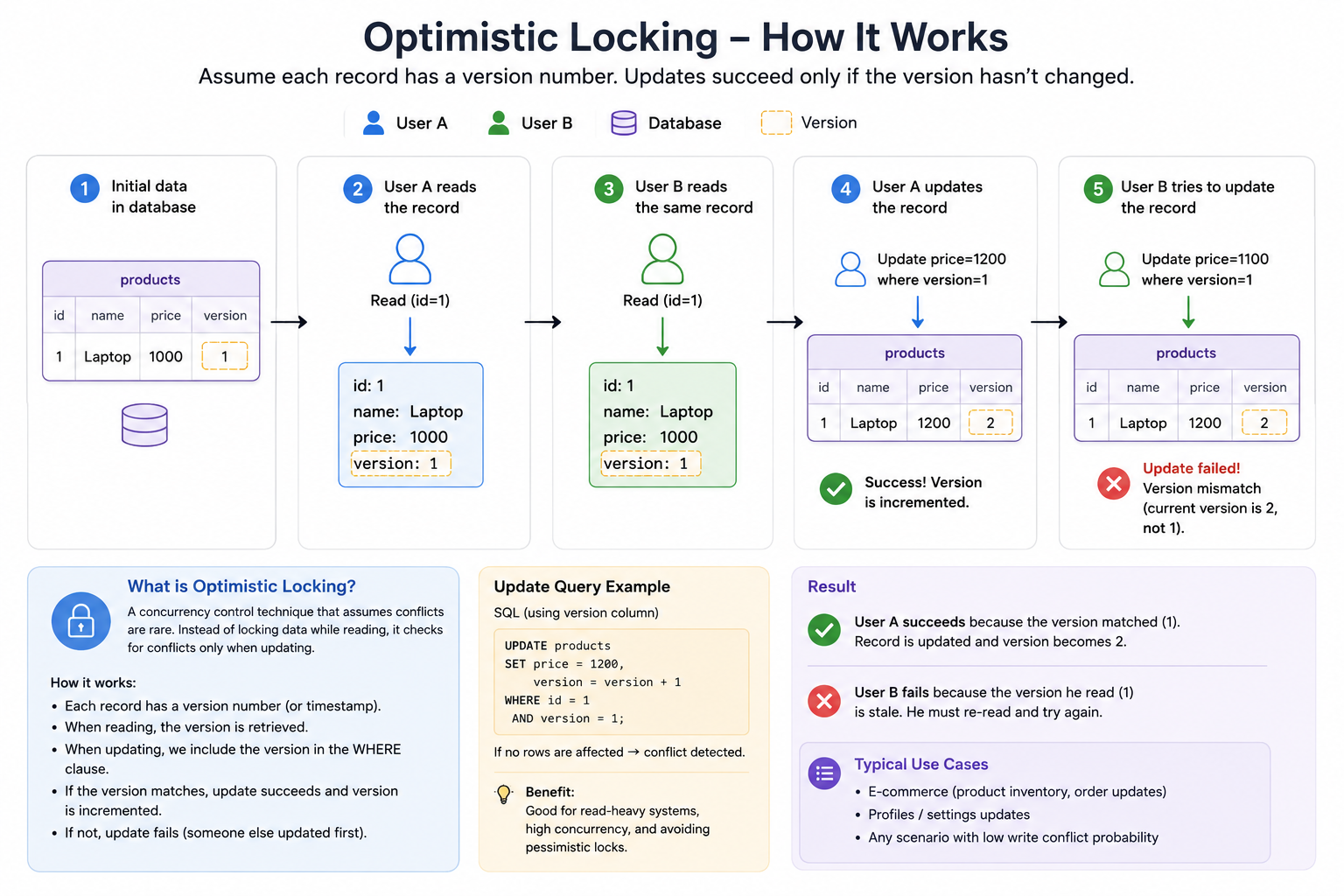
The usual pattern is:
1. Read row with version = 5.
2. Try to update row only if version is still 5.
3. If update succeeds, version becomes 6.
4. If update fails, retry or return conflict.
Example SQL idea:
UPDATE inventory
SET quantity = quantity - 1, version = version + 1
WHERE item_id = ? AND version = ?
Use it when:
- conflicts are rare,
- retry is acceptable,
- you want high throughput,
- blocking would be too expensive.
A good interview phrase:
I would use optimistic locking with a version field. If another request updates the same row first, our update fails and we retry or return a conflict.
Pessimistic locking
Pessimistic locking assumes conflicts are likely.
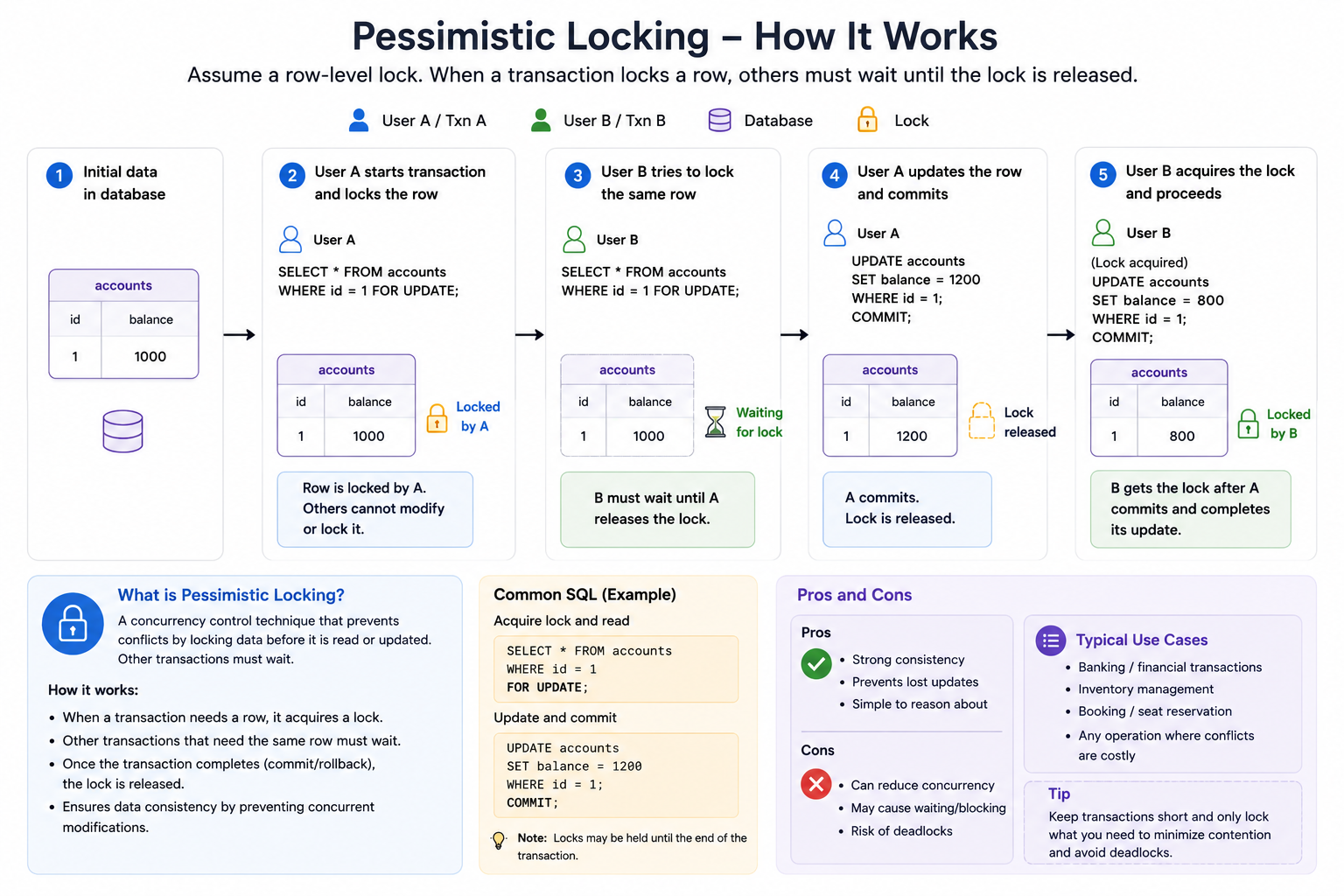
The system locks the row before changing it.
Example:
SELECT * FROM seats
WHERE seat_id = ?
FOR UPDATE
Then only one transaction can update that row at a time.
Use it when:
- conflicts are common,
- correctness is more important than speed,
- retry is hard,
- the operation must be serialized.
Good examples:
- ticket booking,
- inventory decrement,
- bank transfer,
- order confirmation.
A good interview phrase:
For high-contention resources like seats or inventory, I would use a database transaction with row-level locking to make sure only one request can update the resource at a time.
Distributed locking
Distributed locking is used when multiple machines need to coordinate.
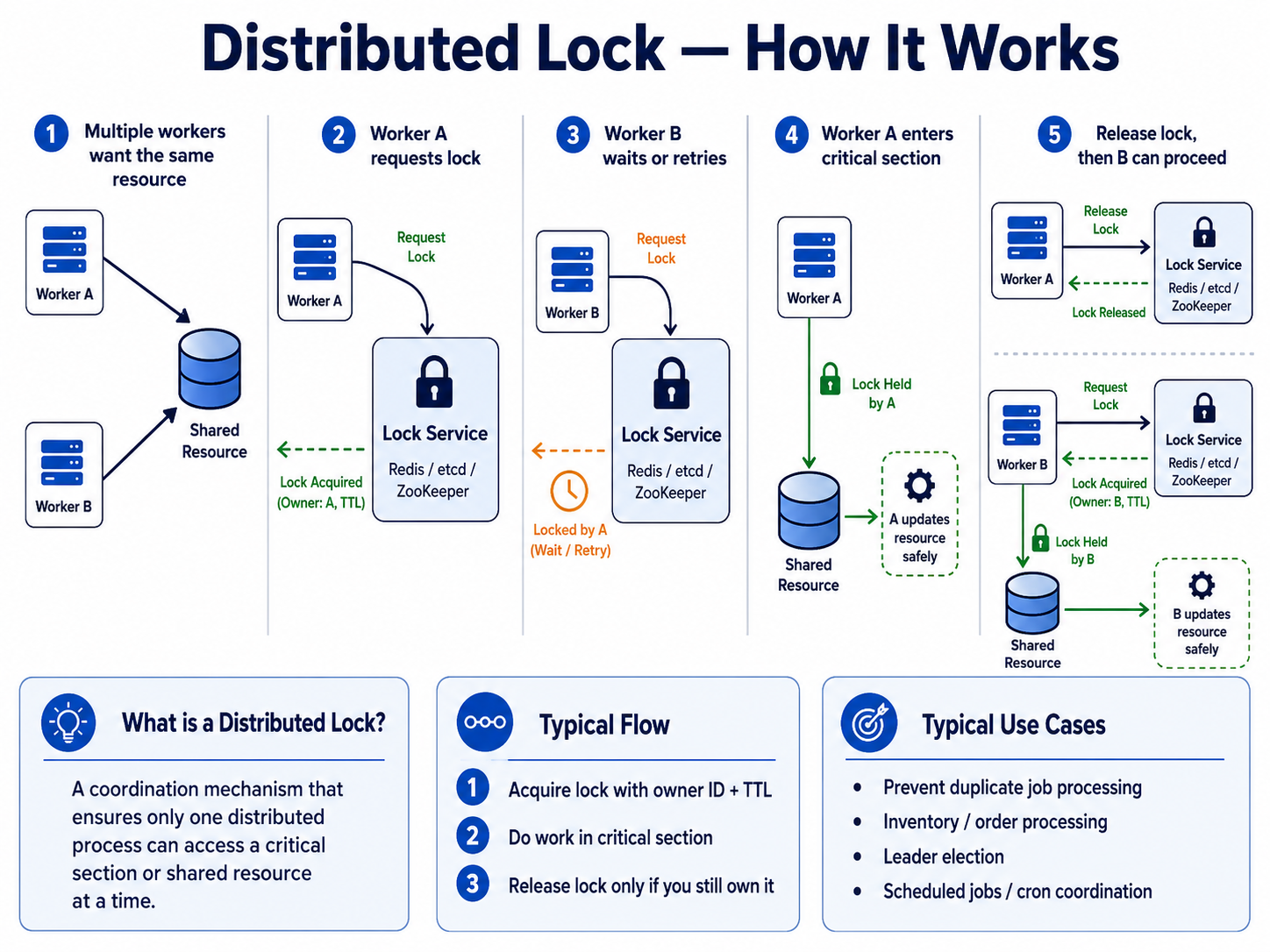
Example:
Worker A and Worker B both want to process job 123.
Only one should get the lock.
Common implementations:
- Redis
SET NX EX, - ZooKeeper,
- database conditional write.
Use it when:
- the lock must work across multiple service instances,
- one worker should own a task,
- a scheduled job should only run once,
- the work is not fully protected by one database transaction.
A good interview phrase:
I would use a distributed lock only if the coordination must happen across multiple service instances. For simple row updates, a database transaction may be enough.
When to use which

Ticket booking example
For ticket booking, the risky part is seat reservation.
A simple flow:
1. User selects seat.
2. Reservation Service starts transaction.
3. Lock the seat row.
4. If seat is available, mark it as reserved.
5. Create reservation with expiration time.
6. Commit transaction.
This prevents two users from reserving the same seat.
If the system has multiple reservation services, the database lock is still enough if all seat state is in the same database row. You do not always need a distributed lock.
Common mistakes
- Saying “use distributed lock” for every concurrency problem.
- Forgetting timeout or expiration for locks.
- Holding a lock while doing slow work like payment.
- Not handling retries.
- Not explaining what happens when lock acquisition fails.
- Forgeting that distributed locks are hard to make safe.
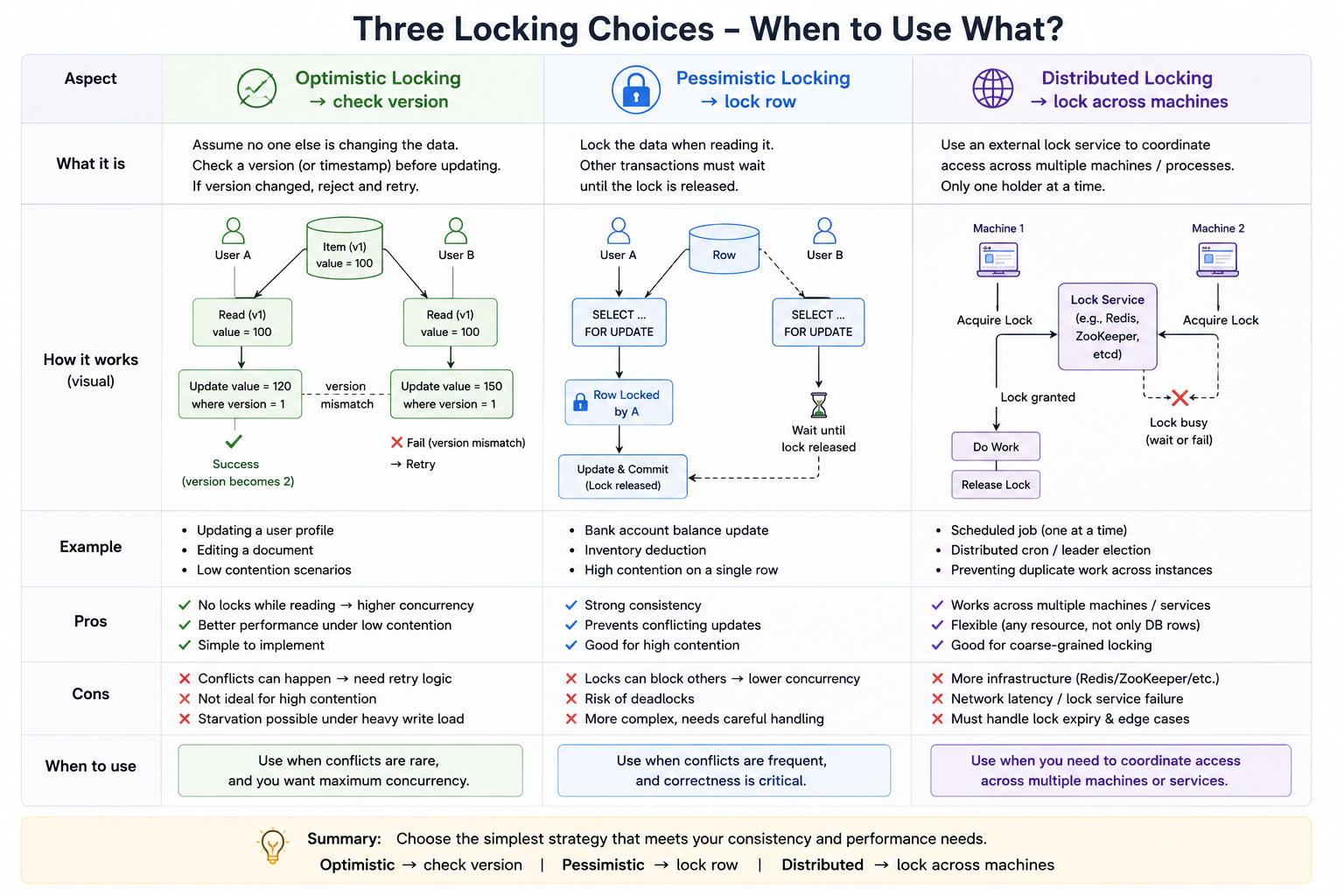
Final takeaway
Do not jump directly to distributed locks.
A strong answer is:
First, I would see if a database transaction or optimistic locking is enough. If the coordination must happen across multiple service instances, then I would consider a distributed lock with expiration and retry handling.