Design Yelp



Problem statement
Short description
Design a proximity service like Yelp: given a user's location, return nearby businesses (restaurants, shops, etc.), optionally filtered by category or rating, and let users view business details and read or leave reviews.
For example, a user at (37.78, -122.41) searches for coffee shops within 2 km, and the system returns the matching businesses sorted by distance.
Understanding the problem
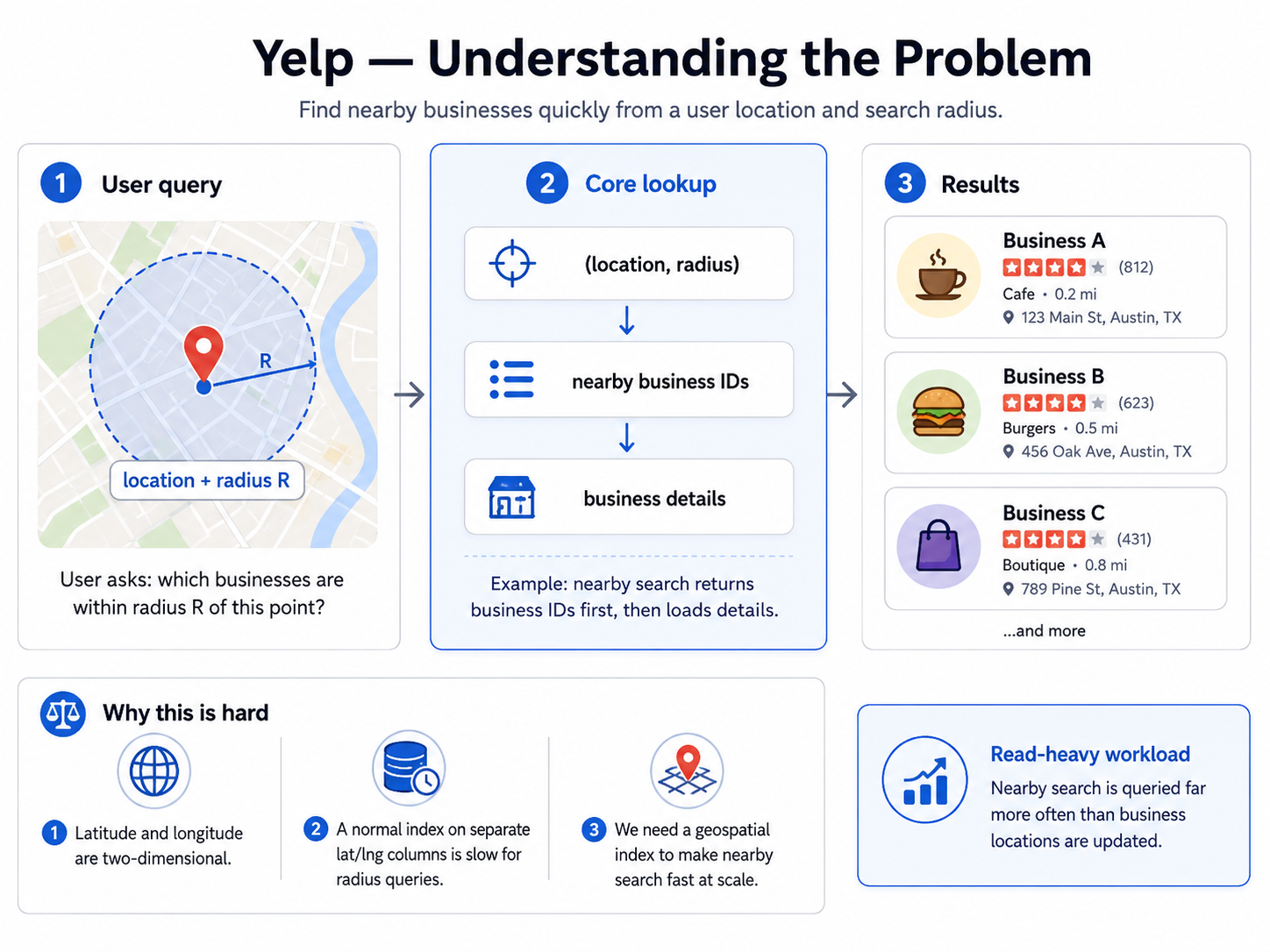
From the statement, the system does one core thing: it answers "which businesses are within radius R of this point?" quickly, then returns their details.
In other words, the core of the system is a spatial lookup:
(location, radius) → nearby business IDs → business details
The key challenge is that latitude/longitude are two-dimensional, and a normal database index on two independent columns is slow for "within a radius" queries. The hard part is building a geospatial index that makes nearby search fast, while serving a very read-heavy workload at scale.
What we need to discuss with the interviewer
Before designing, clarify the boundary of the problem. Pick three to four questions:
- Scale — How many businesses and how many search queries per second do we expect?
- Latency — What is the acceptable p99 for a nearby search?
- Search semantics — Fixed radius, "k nearest," or both? Do we filter by category, rating, open-now?
- Scope — Beyond search, details, and reviews, are photos, personalization, or business onboarding in scope?
For this design, we focus on searching businesses by location/keyword/category, viewing business details with reviews, and leaving reviews. Business onboarding/CRUD, ranking quality, and personalization are follow-ups.
Requirements
Functional requirements
- Search for businesses — Users can search by keyword, category, and location, and filter or sort by rating; results are paginated.
- View business details & reviews — Users can see a business profile with its average rating and paginated reviews.
- Leave a review — Users can rate (1–5 stars) and write a text review; one review per user per business.
Non-functional requirements
- Low latency — Nearby search p99 < 200 ms (interactive path).
- High availability — 99.9%+ for search.
- Scale — ~100M+ businesses, ~10K search QPS (peak higher), read-heavy and global.
- Consistency — Eventual consistency is fine for listings; business writes don't need strong consistency and slightly stale reads are acceptable.
- Accurate ratings — Average ratings stay correct under heavy concurrent reviews (one per user per business), and a new review is reflected within seconds.
A good interview phrase:
I will optimize the search path first because reads dominate, and the central problem is making geospatial lookups fast.
Core entities
We only need a few core entities.
- Business — name, description, category, location (lat/lng), address, average rating, review count
- Review — rating (1–5), text content, author, business ID, timestamp
- User — account info, name, profile
- Location — latitude, longitude; optionally mapped to named areas (city, neighborhood)
The Business is the central entity, and its Location is the field we index on. The spatial index itself is an implementation detail for fast nearby search, so we introduce it in Deep Dive 1 rather than listing it as a core entity.
API design
Search for businesses
GET /v1/search?lat=37.78&lng=-122.41&radius=2000&category=coffee&q=blue+bottle&min_rating=4&sort=rating&page_size=20&page_token=abc
Response:
{
"results": [
{ "business_id": "b_123", "name": "Blue Bottle", "distance_m": 320, "rating": 4.5 },
{ "business_id": "b_456", "name": "Sightglass", "distance_m": 810, "rating": 4.4 }
],
"next_page_token": "def"
}
View business details & reviews
GET /v1/businesses/b_123
GET /v1/businesses/b_123/reviews?page_size=20&page_token=abc
The business response includes average_rating and review_count; reviews are fetched separately and paginated.
Response (GET /v1/businesses/b_123):
{
"business_id": "b_123",
"name": "Blue Bottle",
"category": "coffee",
"address": "66 Mint St",
"average_rating": 4.5,
"review_count": 1280
}
Response (GET /v1/businesses/b_123/reviews):
{
"reviews": [
{ "review_id": "r_1", "user_id": "u_9", "stars": 5, "text": "Great coffee.", "created_at": "2026-06-01T10:00:00Z" }
],
"next_page_token": "def"
}
Leave a review
POST /v1/businesses/b_123/reviews
{
"stars": 5,
"text": "Great coffee and friendly staff."
}
Enforce one review per user per business with a unique constraint on (business_id, user_id); a repeat submission updates the existing review.
Response (201 Created):
{
"review_id": "r_1024",
"business_id": "b_123",
"user_id": "u_9",
"stars": 5,
"text": "Great coffee and friendly staff.",
"created_at": "2026-06-10T21:50:00Z"
}
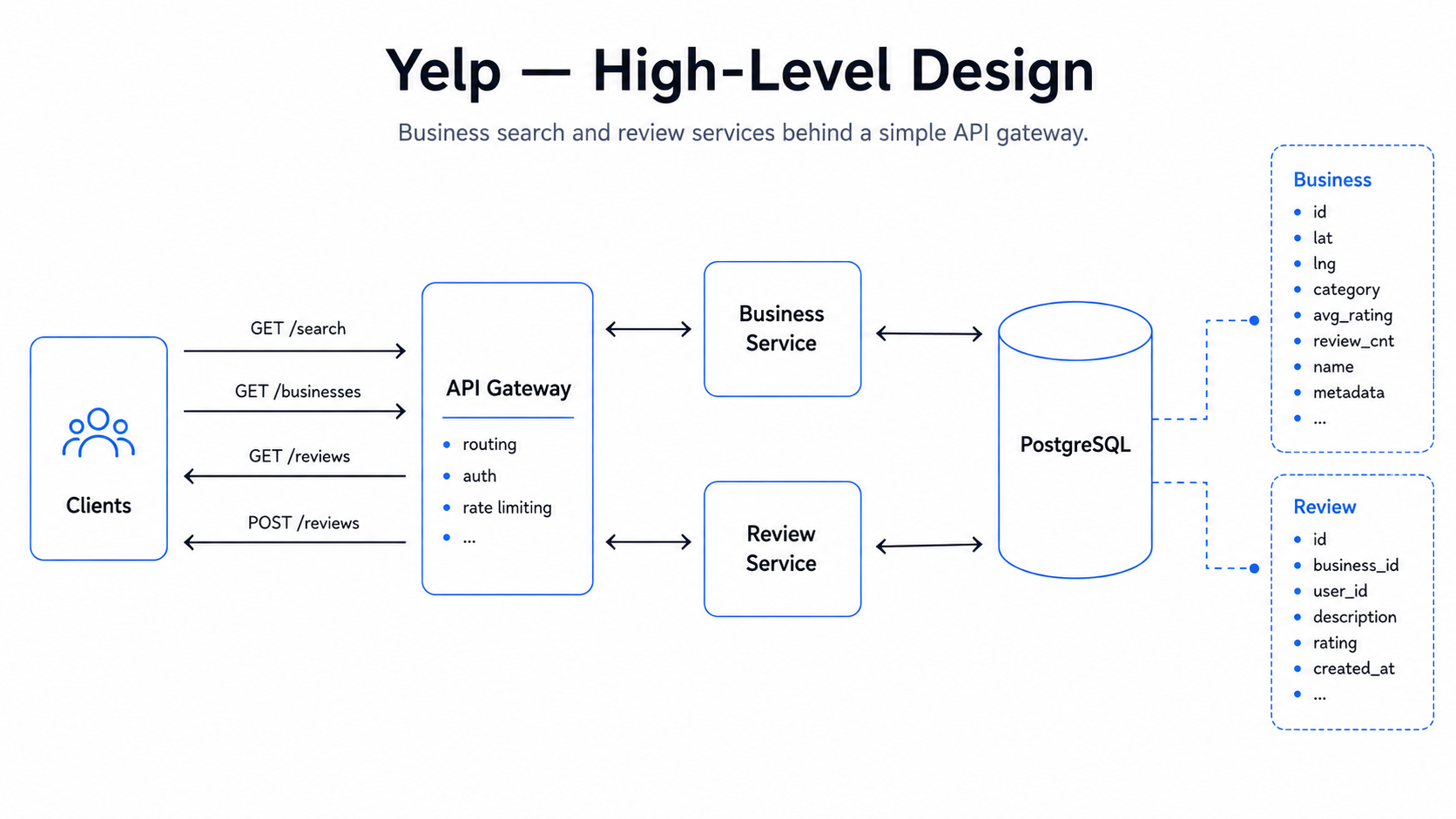
High-level design
The high-level design should match the functional requirements exactly, and only the functional requirements — we leave latency, scale, availability, and consistency tuning to the deep dives. We have three functional requirements, so we design in three steps.
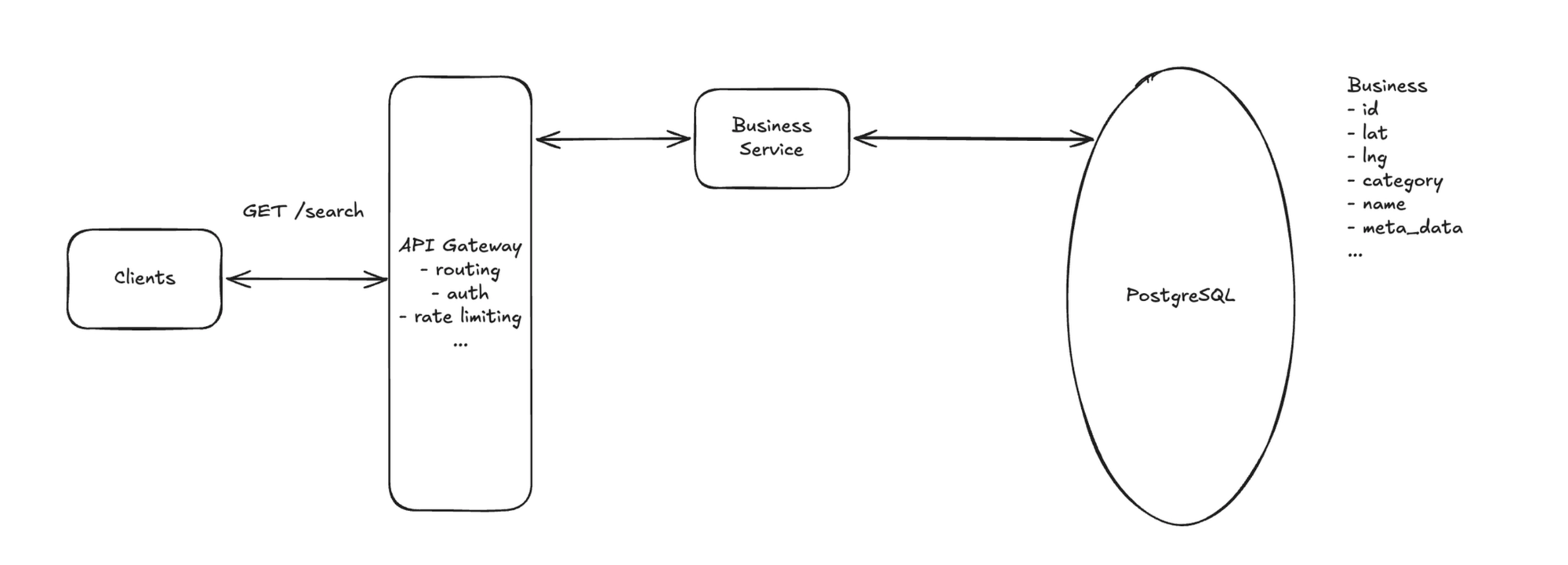
1. Search for businesses
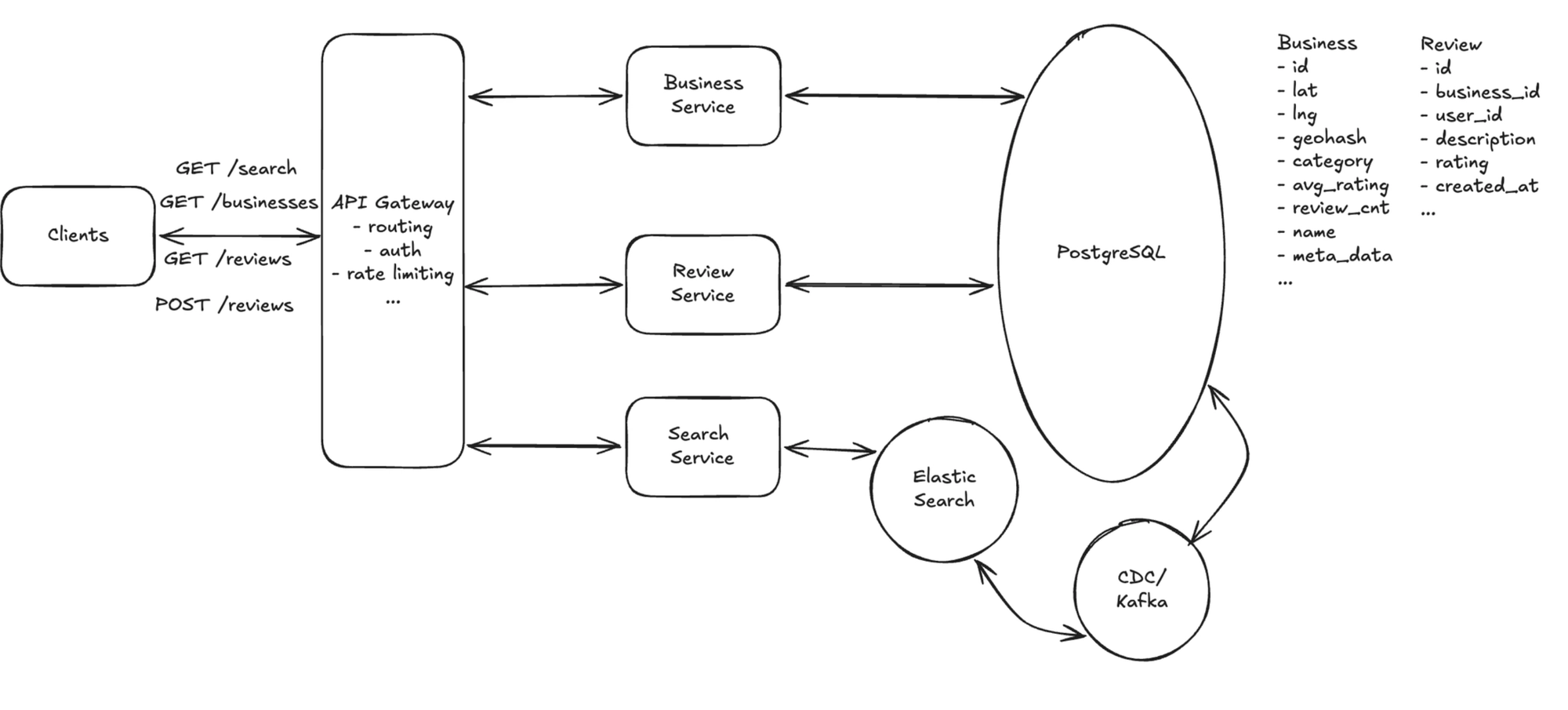
Flow: Client → API Gateway → Business Service → Query Database.
The Search Service finds candidate businesses near the query point using a geospatial index (covered in Deep Dive 1), applies keyword/category and min-rating filters, fetches their details from the Business Service, sorts by distance or rating, and returns a page of results.
Minimal state: the business(business_id, lat, lng, category, name) table, with the spatial index introduced in Deep Dive 1.
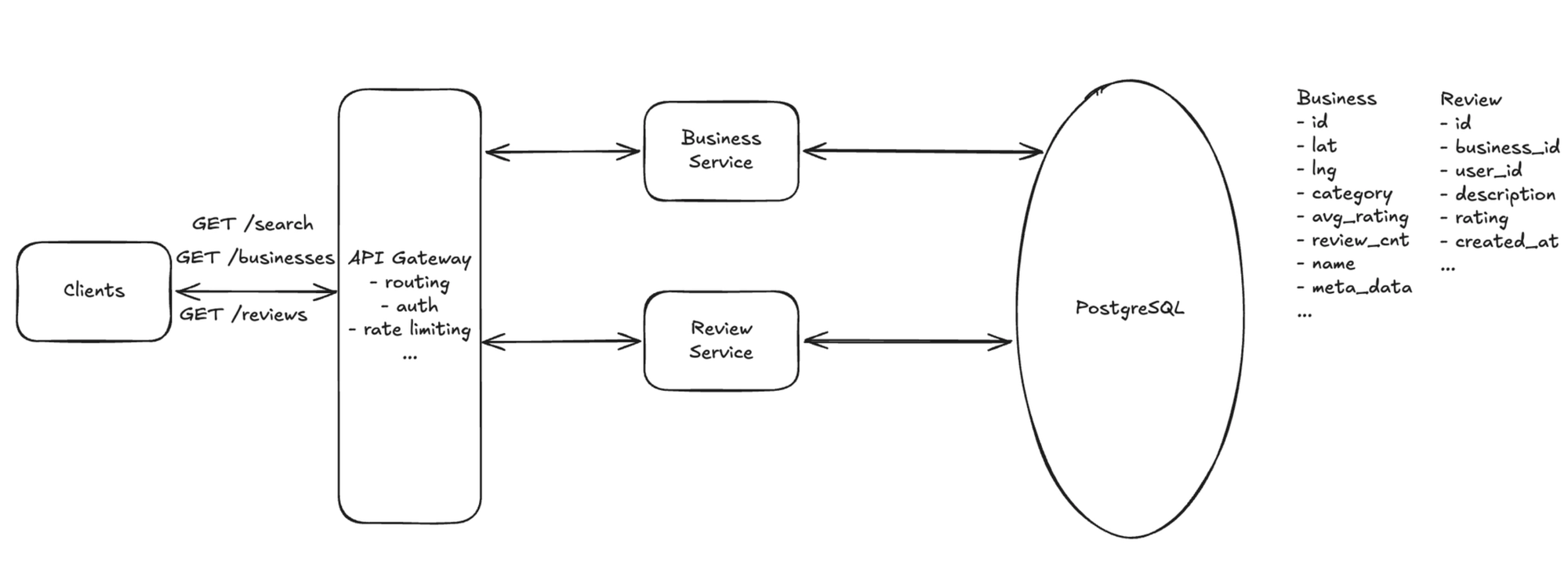
2. View business details & reviews
Flow (two independent reads):
- Business details: Client → API Gateway → Business Service → Business DB — returns the business record including
avg_ratingandreview_count. - Reviews: Client → API Gateway → Review Service → Review DB — reading reviews goes straight to the Review Service, paginated by
business_id; there's no need to route through the Business Service.
The two are separate endpoints with no dependency, so the client can fetch the details and the first page of reviews in parallel.
Minimal state:
business(business_id, name, category, address, avg_rating, review_count)review(review_id, business_id, user_id, stars, text, created_at)— unique on(business_id, user_id)to enforce one review per user, and indexed bybusiness_idso reviews for a business can be paginated efficiently
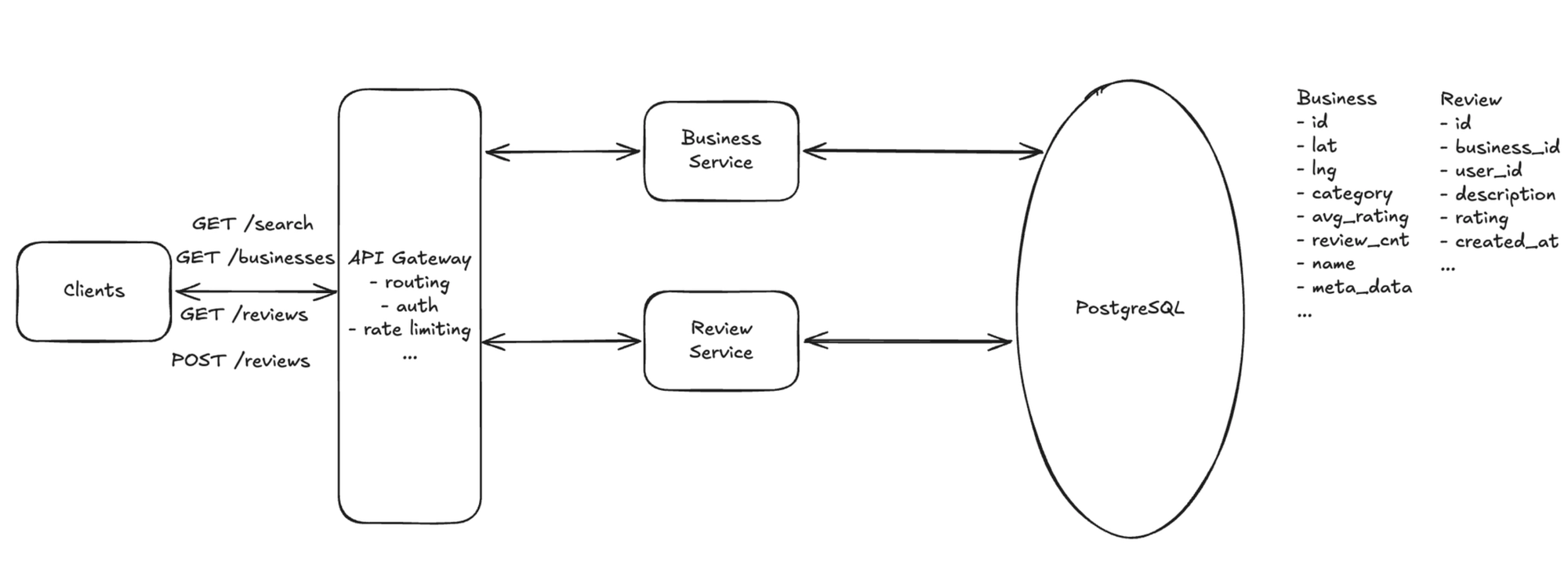
3. Leave a review
Flow: Client → API Gateway → Review Service → write Review DB + update the business rating aggregate.
The service writes the review (enforcing one per user per business) and updates the business's avg_rating and review_count. Uses review + business.
Deep dives
The high-level design satisfies the functional requirements. The purpose of the deep dives is to satisfy the non-functional requirements.
Each deep dive maps back to specific non-functional requirements:
- Search indexing (geo + keyword + filters) → solves Low latency and Scale.
- Scaling a read-heavy workload → solves Scale and High availability.
- Rating computation and updates → solves Accurate ratings and Consistency.
Deep Dive 1: How do we make search fast (geo + keyword + filters)?
This deep dive addresses Low latency and Scale.
Search is more than "within radius R": a single query combines geo proximity, keyword text (name/category), and filters/sorting (category, rating). A plain index on lat and lng can't answer radius queries efficiently because the two dimensions are independent, and it does nothing for text or facets. We need both a 1D key that preserves spatial locality and an engine that can combine all three in one query.

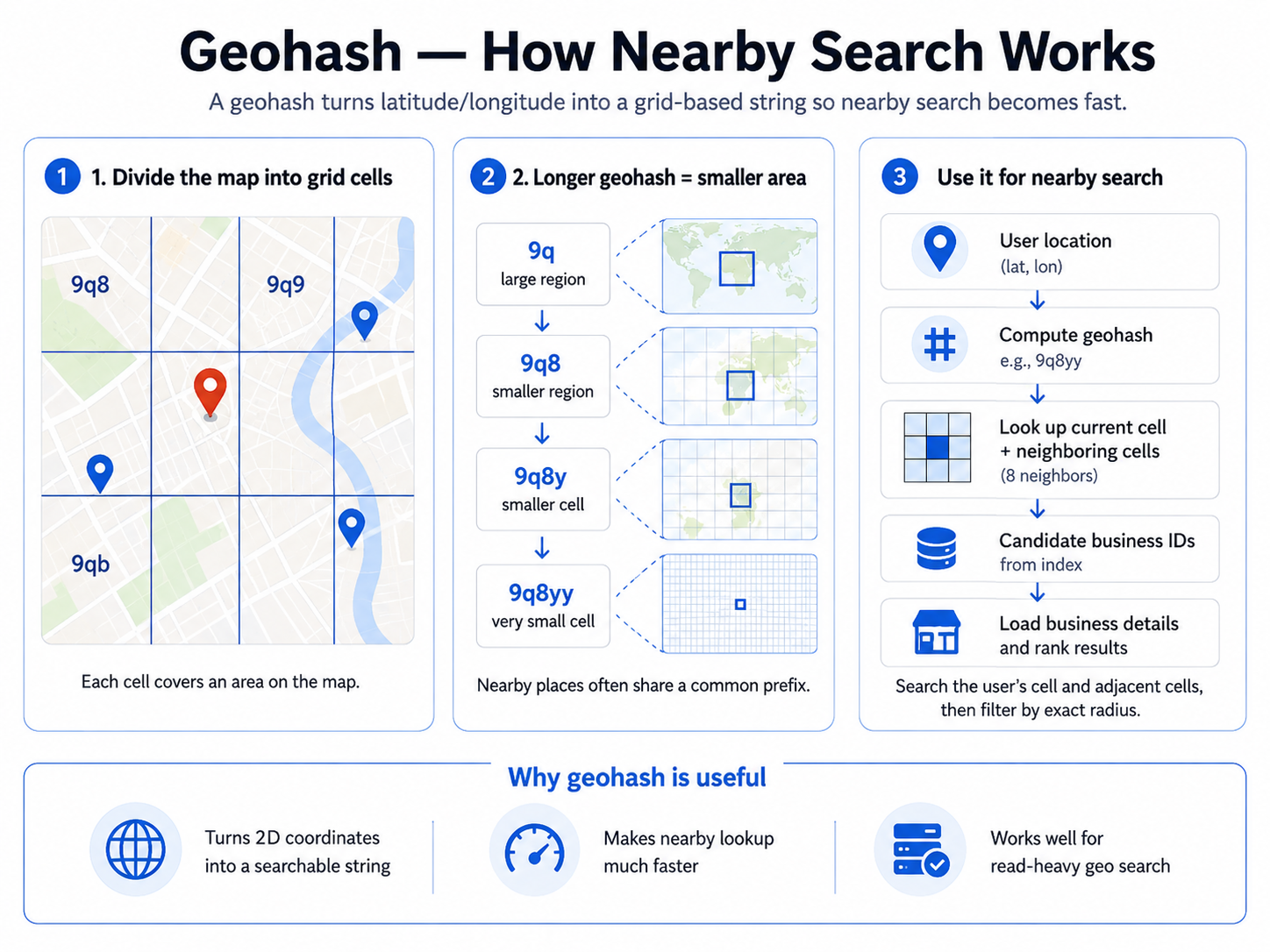
Recommended: a search engine (Elasticsearch) over a geohash/geo index
- One engine for geo + text + filters: index each business with a
geo_point/geohash, an inverted index for name/keywords, and keyword fields for category and rating, so a single Elasticsearch query doesgeo_distance(orgeohash_grid) + full-text match + category/rating filters + sort by distance or rating — exactly the combined query our search FR needs. - Geohash makes "nearby" fast: geohash collapses 2D into a 1D string, so proximity becomes a prefix match; pick the geohash length to match the search radius and scan the cell plus its 8 neighbors to avoid edge misses.
- Scales with density in mind: shard by routing (geohash prefix or region) with replicas for read throughput and availability, and for very uneven density use a quadtree that subdivides only dense areas to keep per-cell counts bounded.
Keeping the index in sync
Elasticsearch is a derived read store, not the source of truth. The business DB stays authoritative, and we feed changes (new business, moved location, updated avg_rating) into ES through a change stream / indexing pipeline. This keeps the write path simple and lets us rebuild the index from the DB if it ever drifts.
Alternatives
- DB geospatial extension (PostGIS / R-tree): accurate and easy to start, but couples search to the primary DB, is weaker at full-text + faceting, and is harder to shard globally.
- Roll-your-own geohash table + separate text index: workable, but you end up reinventing what a search engine already gives you (combined geo + text + filter + sort).
- Google S2 cells: excellent spherical accuracy, but more complex to explain and implement in an interview.
Deep Dive 2: How do we scale a read-heavy workload?
This deep dive addresses Scale and High availability.
Searches and detail views massively outnumber edits, so the read path is the hot path.
Recommended: cache + replicas + sharding
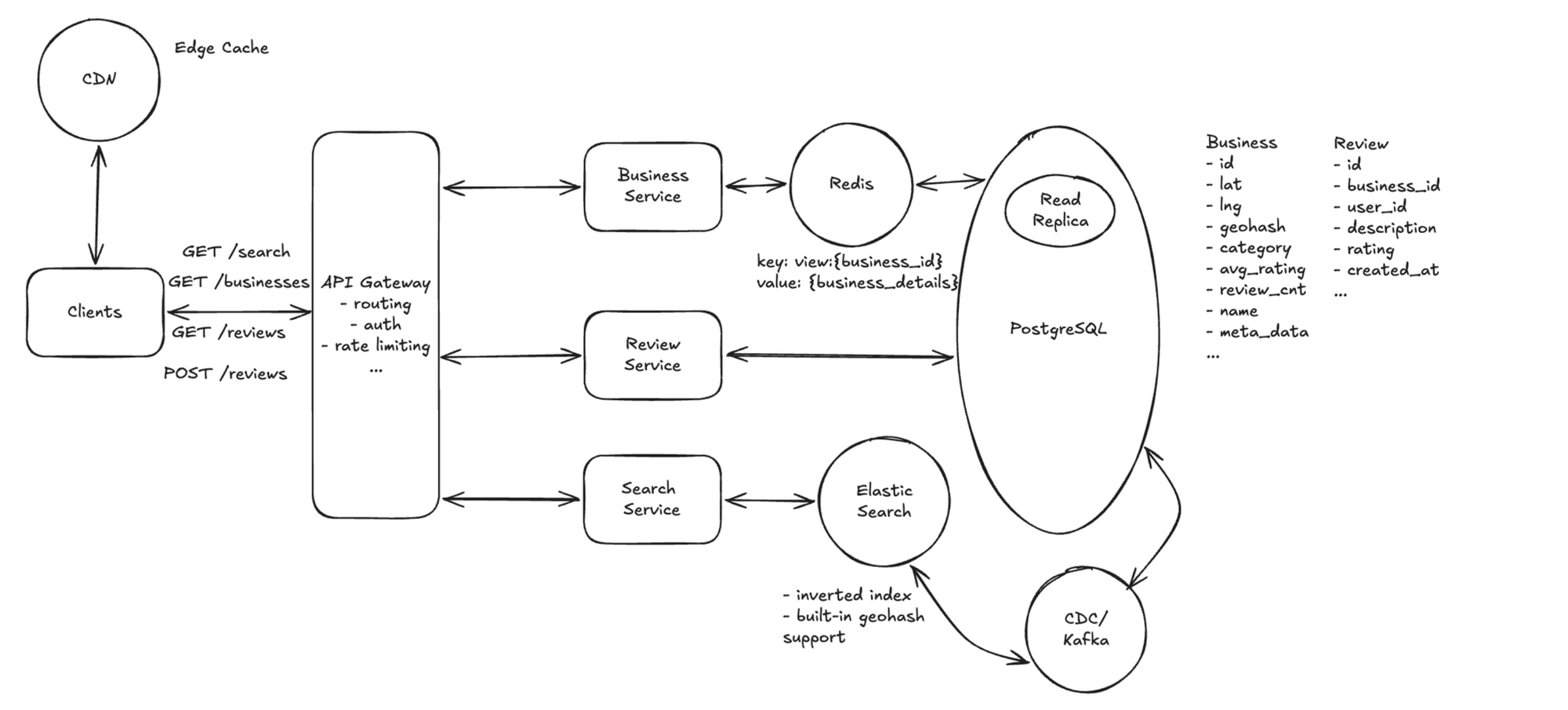
- Cache hot cells and businesses: keep popular geo cells and business details in Redis, so most searches hit memory instead of the DB.
- Replicate and shard the data layer: route reads to replicas (primary handles only writes) and shard by geohash prefix, so load spreads across nodes and each query touches few shards.
- Stateless search services behind a load balancer: scale them horizontally for throughput and availability.
Alternatives
- Single powerful DB with geospatial extension: simplest operationally, but becomes a bottleneck and single point of failure at high QPS.
- Precompute results per popular query: ultra-fast for common searches, but storage-heavy and stale for the long tail of locations.
Deep Dive 3: How do we compute and update business ratings at scale?
This deep dive addresses Accurate ratings and Consistency.
Reviews are the main write path, and a popular business can receive a burst of reviews at once. Recomputing AVG(stars) over all reviews on every read is too slow, and naively updating one rating row creates write contention and lost-update races.
Recommended: running total + delta updates + async aggregation
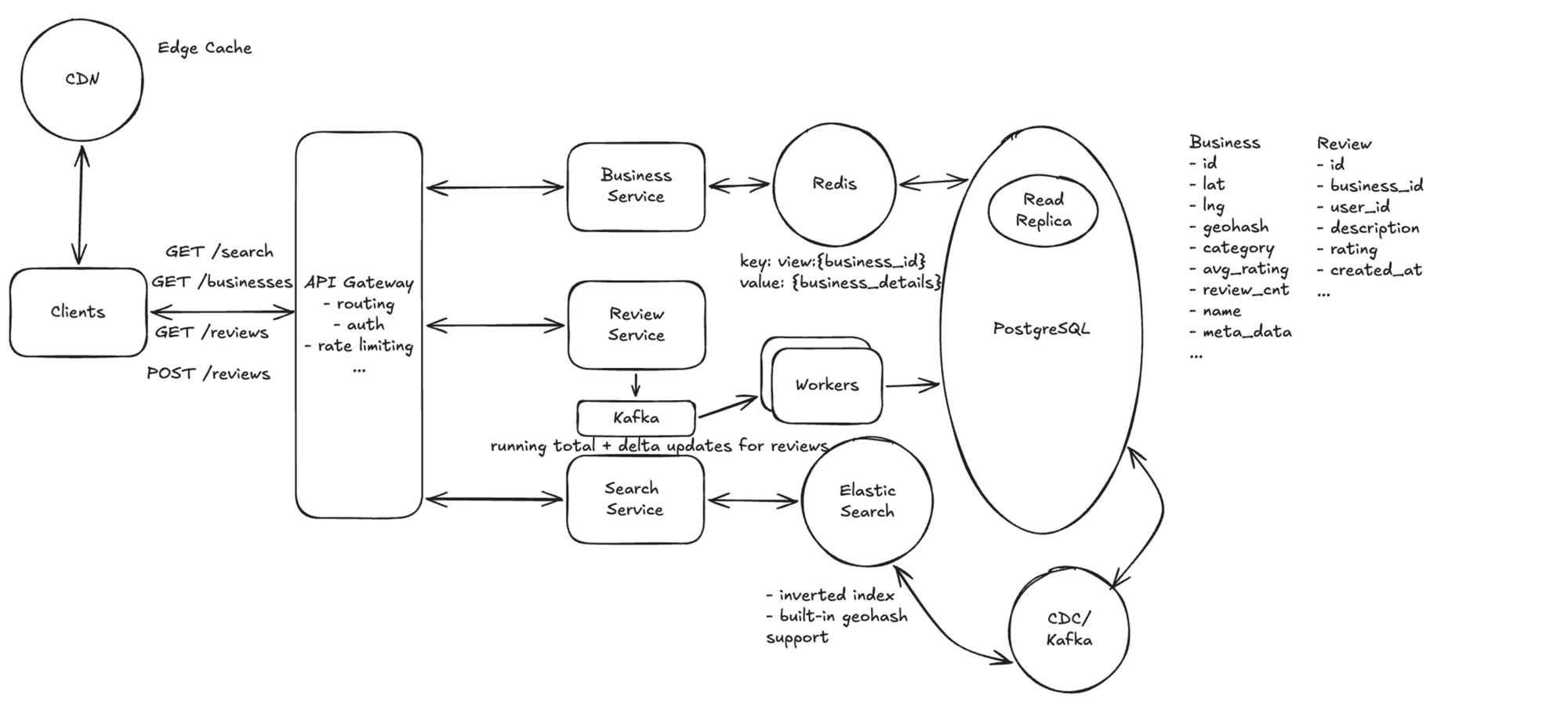
In one line: keep each business's average as a running total, nudge it up or down with a tiny delta on every review instead of recomputing, and make those updates safe to retry.
- Store the average as a running total — the what: keep
rating_sum(the sum of all stars) andreview_counton the business and serveavg_rating = rating_sum / review_count, so reads are O(1) and never scan the reviews table. The reviews themselves stay the source of truth, so the totals can always be rebuilt if they ever drift. (This bullet is only about how the value is stored and read.) - Update it with an atomic delta — the how: given that running total, keep it correct on writes by adjusting it in place with one atomic statement instead of re-summing. A new 4★ review runs
UPDATE business SET rating_sum = rating_sum + 4, review_count = review_count + 1 WHERE business_id = ?; editing that review from 4★ to 5★ appliesrating_sum += (5 − 4)and leaves the count unchanged. Because the database does that increment atomically and addition is commutative, concurrent reviews can't lose updates. A unique(business_id, user_id)constraint keeps it to one review per user, so a re-submission edits that user's existing review (a delta) rather than adding a row; and tagging each delta with itsreview_idlets a retried write be ignored, so the same review is never counted twice. - Absorb hot businesses asynchronously: publish review events to a queue/stream and let an aggregation worker fold them into the business total, so a viral business getting a burst of reviews doesn't hot-spot a single row on the synchronous write path.
Why this is a strong answer
- O(1) reads:
avg_ratingis precomputed, so detail views and rating-sorted search never aggregate at query time. - Correct under concurrency: delta updates plus idempotency keys avoid lost updates and double counting.
- Resilient: because reviews are the source of truth, the aggregate can be recomputed or backfilled if it ever drifts.
- The few-seconds lag before a new rating is reflected fits our eventual-consistency NFR.
Wrap up and final design
At the end, briefly summarize the architecture and confirm it satisfies both functional and non-functional requirements.
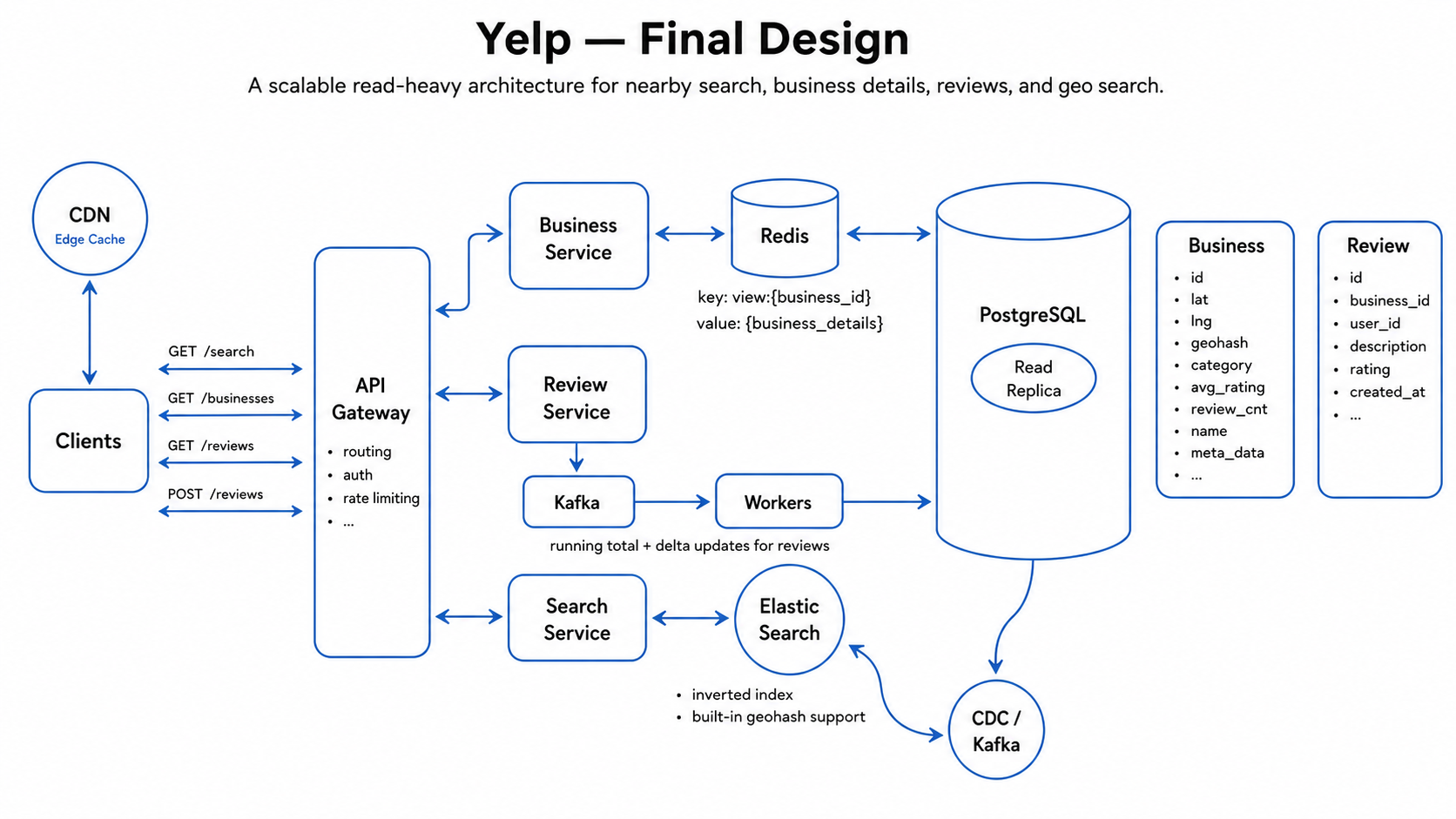
Final design
- Read path (search + details): Client → API Gateway → Search Service → Elasticsearch (geo + keyword + filters, sharded by geohash, replicated) to get candidate businesses, then Business Service → Business DB (read replicas + Redis cache) for details and
avg_rating; reviews are read separately and paginated. Results return sorted by distance or rating. - Write path (leave a review): Client → API Gateway → Review Service → Review DB (unique one review per user per business), which atomically updates the business
rating_sumandreview_count; the same review event is streamed to the search index so Elasticsearch stays in sync. - Critical design: the rating aggregate is maintained with idempotent atomic deltas and hot businesses are absorbed asynchronously through a queue/stream, while the geo + text index is a derived read store kept in sync from the authoritative business DB and rebuilt on drift or density-driven resharding.
Requirements coverage
All three functional requirements — search for businesses, view details & reviews, and leave a review — are handled by the paths above. The non-functional requirements map to the three deep dives: low latency and scale to geospatial indexing, availability and read-heavy scale to caching with replicas and sharding, and accurate ratings and consistency under concurrent reviews to incremental, idempotent rating aggregation.
Interview expectations by level
Different levels are expected to go into different depths. The goal is the right depth, not saying everything.
Junior to Mid-level
Expected focus:
- Understand the problem and clarify radius vs k-nearest and scale.
- Design the core search → spatial index → details flow, plus the basic write path for leaving a review.
- Explain why a plain (lat, lng) index is insufficient and why we need a spatial index.
- Describe the business and review tables and the detail + review APIs.
Strong signal:
The candidate recognizes that geospatial search needs a specialized index, not two normal column indexes.
Senior
Expected focus:
- Explain geohash or quadtree, and how a search engine like Elasticsearch combines geo, keyword, and filter/sort in one query.
- Optimize the read-heavy path with caching, replicas, and sharding by cell.
- Discuss filtering (category, rating) and sorting by distance or rating after candidate retrieval.
- Maintain
avg_ratingwith a running aggregate, handling concurrent reviews and one review per user. - Justify eventual consistency for listings and ratings to enable caching.
Strong signal:
The candidate reasons clearly about the indexing tradeoffs and how reads scale, not just which components to use.
Staff+
Expected focus:
- Handle uneven density with adaptive (quadtree/S2) cells and bounded per-cell counts.
- Discuss global distribution, hot-region handling, and index rebuild strategy.
- Keep ratings correct under hot-business write bursts: idempotent atomic deltas with async aggregation, and recompute/backfill if the aggregate ever drifts.
- Identify the key tradeoff: index precision and freshness vs query cost and write amplification.
Strong signal:
The candidate designs for real-world density skew and operational realities while keeping the common case fast.