Database


Your job is not to name a database randomly. Your job is to explain what data you need to store, how you will query it, and what consistency you need.What a database does
A database stores the main business data of your system.
Examples:
- users
- orders
- payments
- posts
- messages
- products
- URL mappings
- inventory records
In most interviews, the database is the source of truth. Other systems like cache or search index may copy data from it, but the database is where the real record lives.
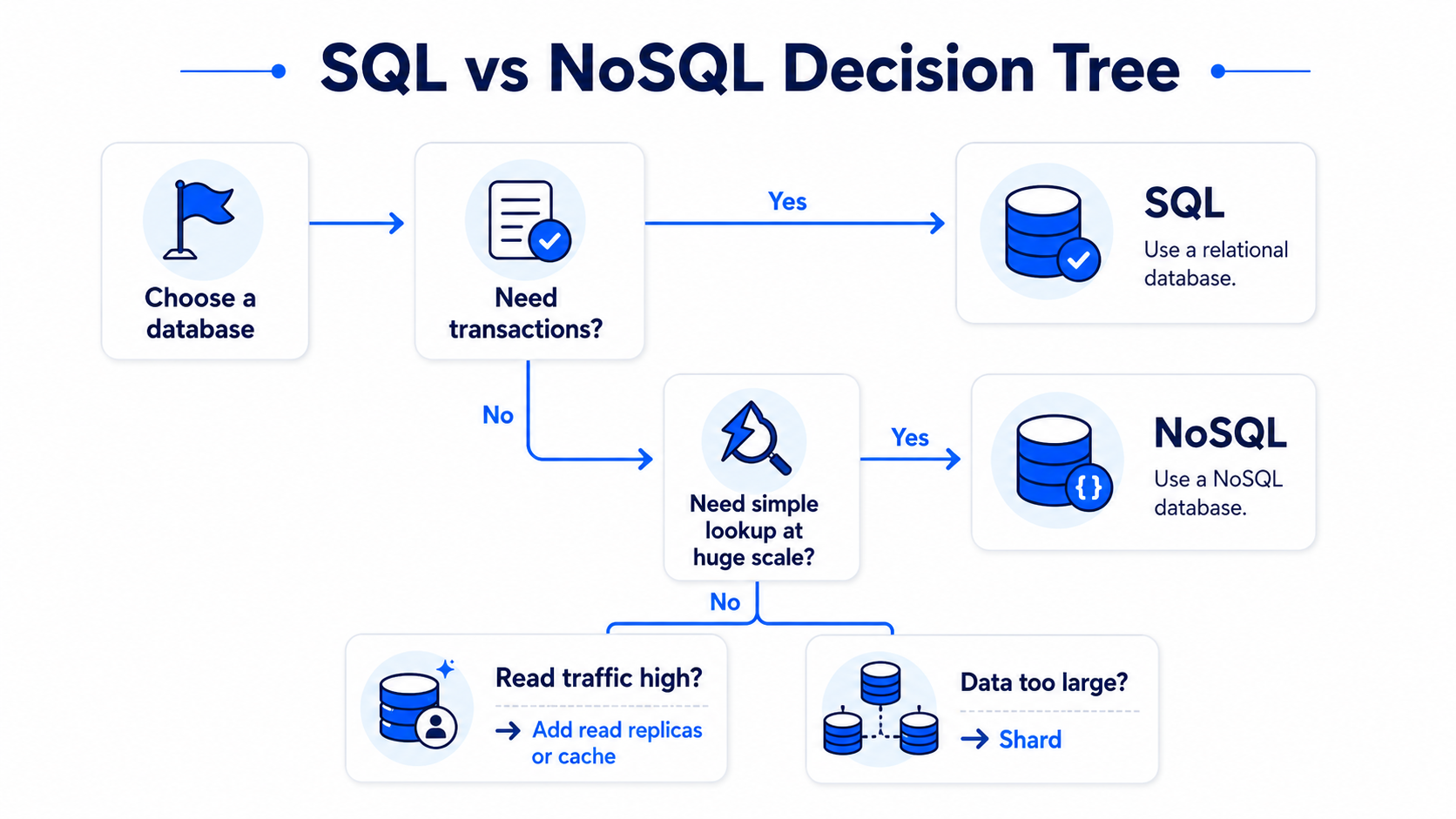
SQL vs NoSQL
The first decision is often simple:
Should we use SQL or NoSQL?
Do not overcomplicate this. In interviews, a good default is:
Start with SQL unless there is a strong reason not to.
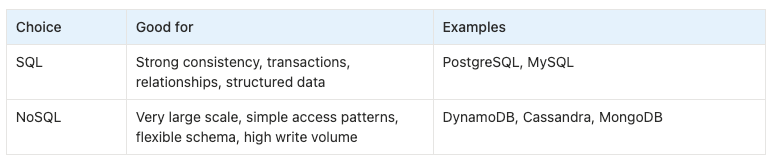
When to choose SQL
Choose SQL when you need correctness and relationships.
Good signals:
- money cannot be wrong,
- inventory cannot be double-sold,
- orders need transactions,
- data has clear relationships,
- you need joins or constraints,
- you need strong consistency.
Examples:
- payment system,
- ticket booking,
- food delivery order,
- inventory management,
- URL shortener mapping with unique short codes.
A good interview sentence:
I would start with PostgreSQL because the data is structured and we need strong consistency for writes.
When to choose NoSQL
Choose NoSQL when the scale is very large and the access pattern is simple.
Good signals:
- millions of writes per second,
- huge amount of data,
- simple key-value lookup,
- flexible schema,
- eventual consistency is acceptable,
- horizontal scaling is more important than complex queries.
Examples:
- activity logs,
- time-series events,
- user sessions,
- click stream,
- large-scale messaging metadata,
- high-volume feed events.
A good interview sentence:
If the write volume becomes extremely high and the access pattern is mostly key-value, I would consider DynamoDB or Cassandra for easier horizontal scaling.
Common NoSQL types

How to talk about database scaling
You do not need to explain every database internals topic. But you should know the basic scaling ideas.
Read replicas
If read traffic is high, add read replicas.
Writes → Primary DB
Reads → Read Replicas
Tradeoff:
Read replicas can have replication lag, so some reads may be slightly stale.
Sharding
If one database cannot hold all data or handle all traffic, split data across shards.
shard_id = hash(user_id) % number_of_shards
Tradeoff:
Sharding increases capacity, but makes cross-shard queries and operations harder.
Indexes
Indexes make reads faster for common query patterns.
Example:
SELECT * FROM orders WHERE user_id = ?
If this query is common, add an index on user_id.
Tradeoff:
Indexes speed up reads, but slow down writes and take extra storage.
URL Shortener example
For a URL shortener, the main table might be:
url_mappings
- short_code
- long_url
- user_id
- created_at
- expires_at
Why SQL works well here:
short_codemust be unique,- each write should be strongly consistent,
- the schema is simple,
- reads are simple key lookups.
If read traffic becomes very high, do not immediately replace the database. Add a cache first.
A good answer:
I would store the short_code to long_url mapping in PostgreSQL with a unique index on short_code. Since redirects are read-heavy, I would add Redis in front of the database to reduce read load.
Common mistakes
- Choosing NoSQL just because it sounds scalable.
- Using SQL without explaining indexes or query patterns.
- Ignoring consistency requirements.
- Storing large files directly inside the database.
- Forgetting that cache and search index are not usually the source of truth.
Final takeaway
In most interviews, start simple:
Use SQL for structured, consistent business data.
Move to NoSQL only when you can clearly explain why:
The scale is too large, the access pattern is simple, and eventual consistency is acceptable.