Cache


A cache is a fast storage layer used to reduce latency and database load.
In system design interviews, cache is one of the most common tools, but you should only use it when the read pattern makes sense.What a cache does
A cache stores frequently accessed data in memory.
Instead of reading from the database every time, the service checks the cache first.
Client → Service → Cache → Database
If the data is in cache, the response is fast. If not, the service reads from the database and may store the result in cache for next time.
Why cache helps
A database read may take:
5–50 ms
A Redis read may take:
0.5–2 ms
That difference matters when you have high read traffic.
Cache is especially useful when:
- reads are much higher than writes,
- the same data is requested again and again,
- slightly stale data is acceptable,
- latency matters,
- database load is becoming too high.
When to use cache
Good interview signals:
- “This is read-heavy.”
- “The same item is viewed many times.”
- “We need low latency.”
- “The database is getting too many reads.”
- “Some data is hot.”
Examples:
- URL shortener redirects,
- user profiles,
- product detail pages,
- news feed ranking results,
- popular posts,
- restaurant details.
When not to use cache
Cache is not always the answer.
Be careful when:
- writes are much higher than reads,
- data must always be fresh,
- every user sees completely different data,
- the data is rarely read again,
- the system is still small.
A good sentence:
I would add cache only if the read traffic is high enough to justify the extra complexity.
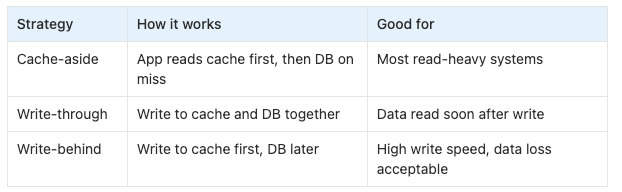
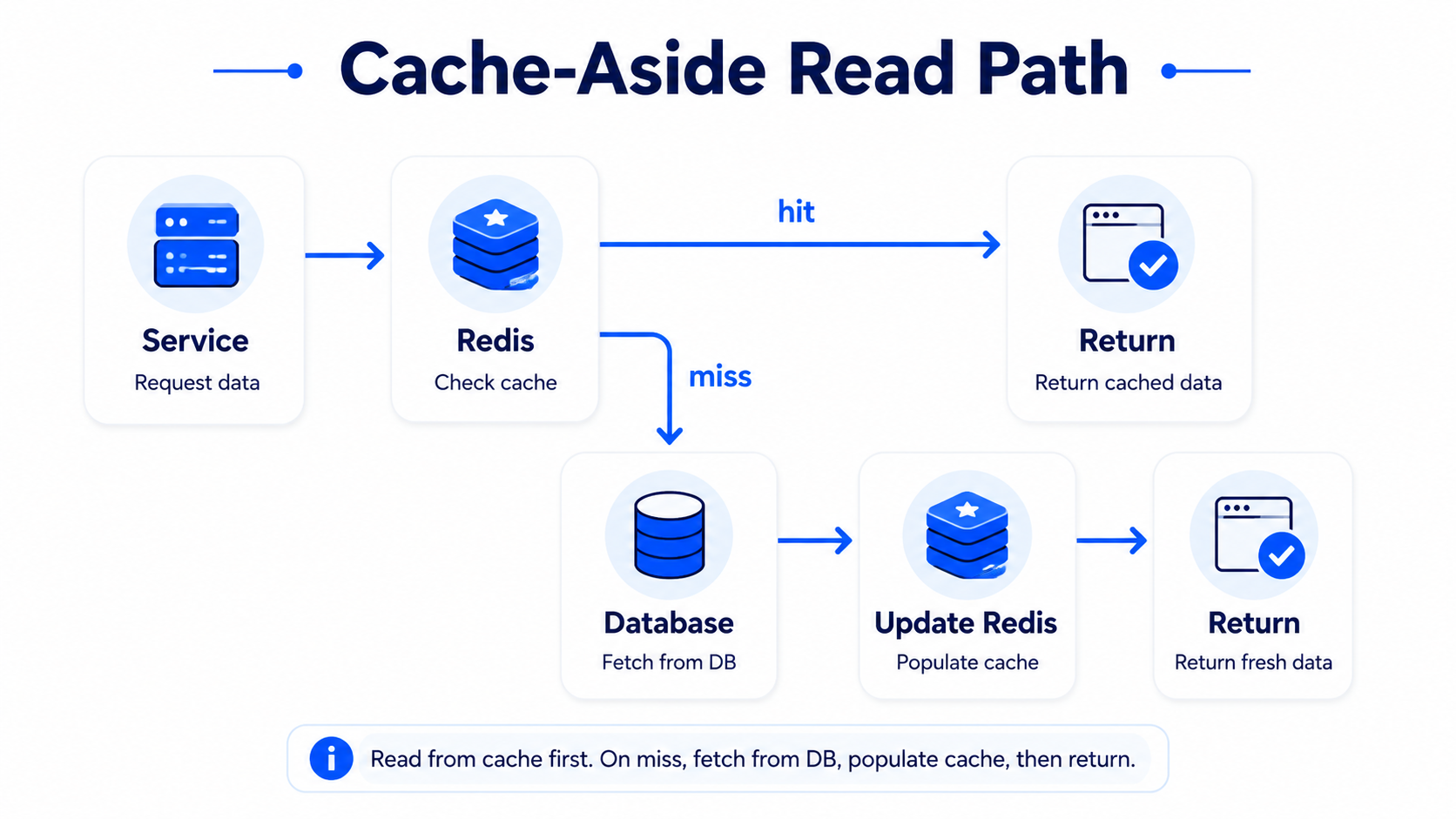
The most common strategy: cache-aside
Cache-aside is the default strategy in many interviews.
Read path:
1. Service checks cache.
2. If cache hit, return data.
3. If cache miss, read from database.
4. Store result in cache.
5. Return data.
Write path:
1. Write to database.
2. Invalidate or update cache.
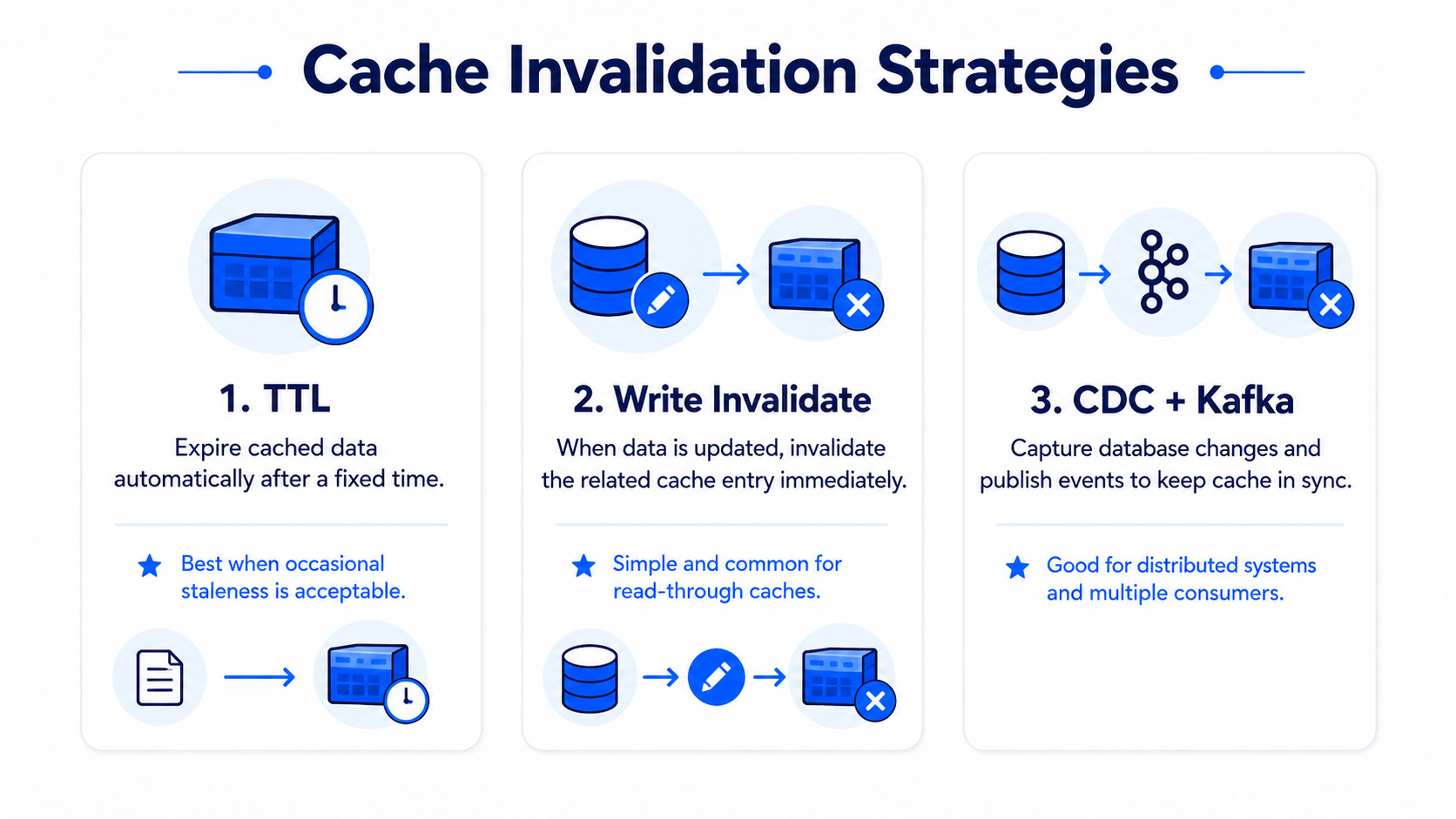
Cache invalidation
URL Shortener example
For a URL shortener, redirect is read-heavy.
The mapping is:
short_code → long_url
This is a great cache use case because:
- redirects are much more common than new URL creation,
- mappings rarely change,
- latency should be low,
- popular links may be clicked many times.
A good interview answer:
I would put Redis in front of the database using cache-aside. The key is the short code and the value is the long URL. Since URL mappings are mostly immutable, cache invalidation is simple. We can use TTL based on the URL expiration time.
Common cache problems
Cache stampede
A hot key expires, and many requests hit the database at the same time.
Fixes:
- add a lock so only one request rebuilds the cache,
- use random TTL,
- refresh hot keys before expiration.
Hot key
One key receives too much traffic.
Example:
a celebrity shares one short link
Fixes:
- replicate hot keys,
- split traffic across cache replicas,
- use CDN if the response is cacheable.
Cold start
After deploy or restart, cache is empty.
Fixes:
- pre-warm cache with hot data,
- allow gradual traffic ramp-up.
Common mistakes
- Adding cache without explaining what is cached.
- Forgetting cache invalidation.
- Using cache for data that must always be strongly consistent.
- Treating cache as the source of truth.
- Ignoring hot keys.
Final takeaway
Cache is best when the system is read-heavy and the same data is requested often.
A strong answer is not:
Add Redis.
A strong answer is:
I would cache this specific data because it is read-heavy, mostly stable, and expensive to fetch from the database. The main tradeoff is staleness, so I would use TTL or invalidation.