Bloom Filter


A Bloom filter is a memory-efficient way to answer one question: “Have we maybe seen this item before?”
It is useful when you want to avoid expensive lookups for items that definitely do not exist.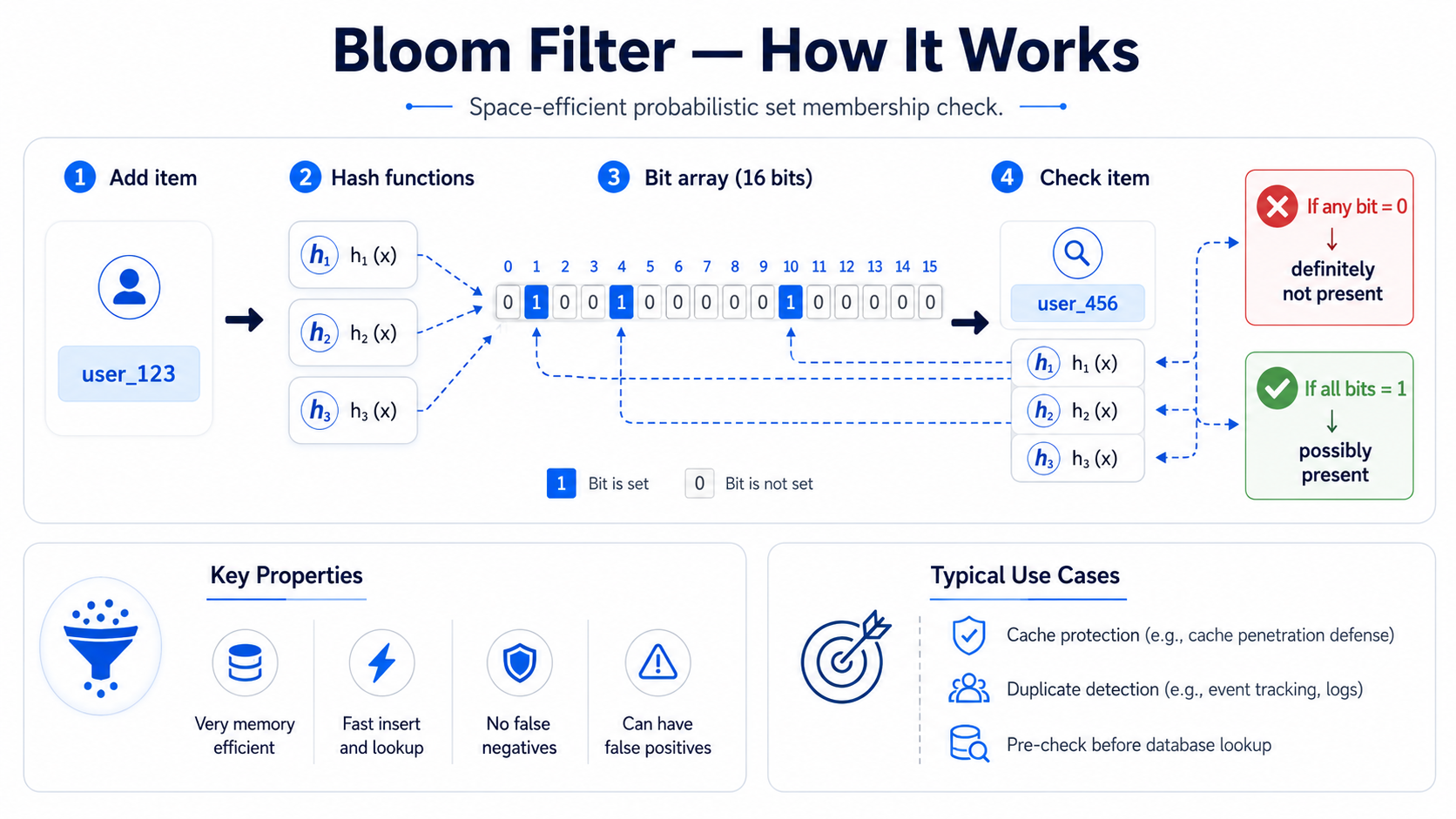
The simple idea

A Bloom filter is a probabilistic data structure.
It can answer:
Definitely not present
Maybe present
It cannot answer:
Definitely present
This is the key tradeoff.
A Bloom filter can have false positives, but it does not have false negatives.
What that means
If the Bloom filter says:
No
Then the item is definitely not in the set.
If it says:
Maybe
Then the item might be in the set, so you still check the database or storage.

When to use Bloom filters
Good interview signals:
- many requests are for missing data,
- database lookups are expensive,
- you need large-scale deduplication,
- you want a memory-efficient pre-check,
- false positives are acceptable.
Examples:
- URL shortener: check if a custom alias may already exist,
- web crawler: check if URL was already seen,
- cache penetration: avoid DB lookups for invalid keys,
- username availability check,
- blocked IP or URL lookup,
- duplicate event detection.
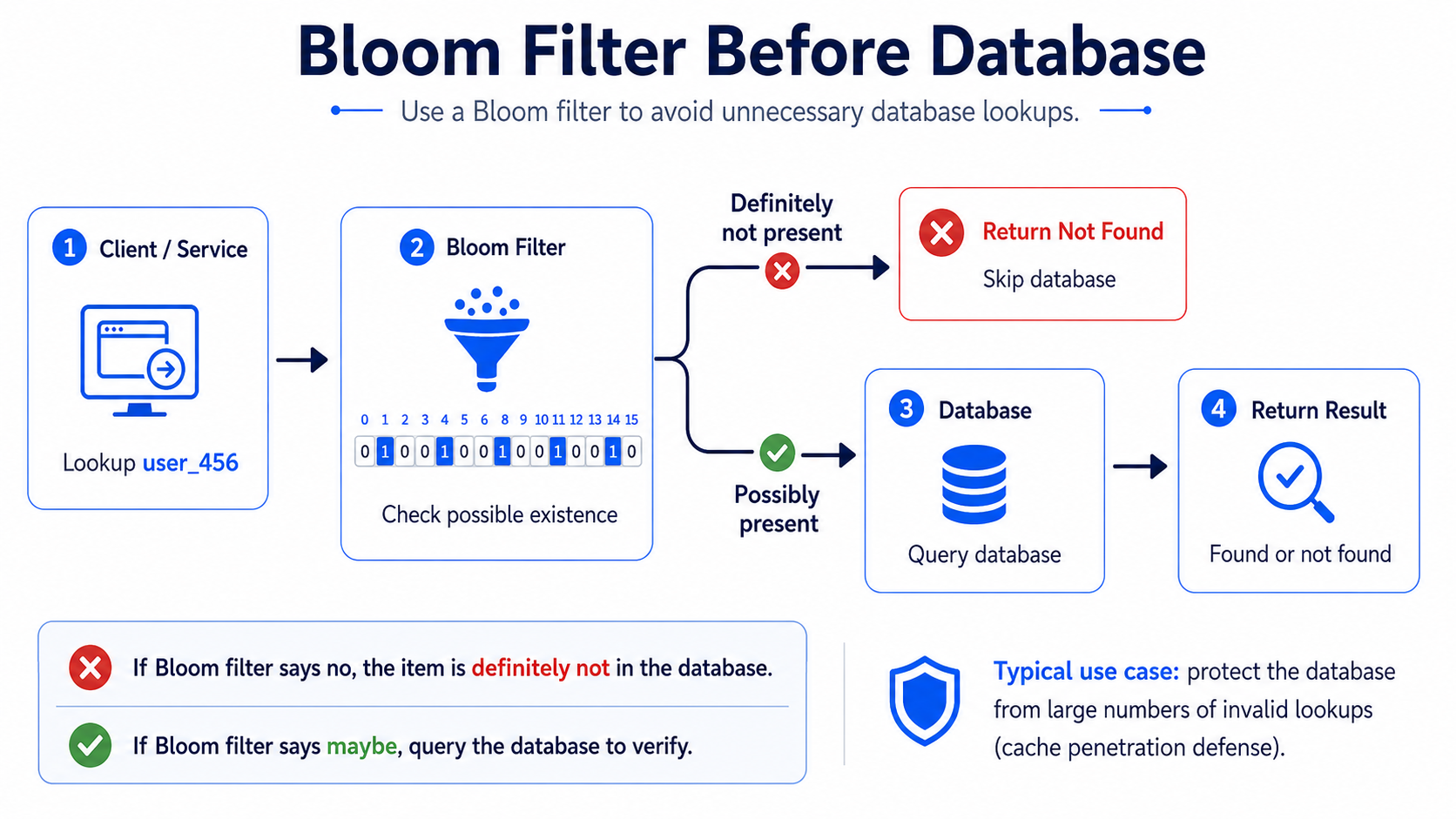
Cache penetration example
Imagine users request many fake IDs:
/item/abc123
/item/fake999
/item/not-real
If these IDs do not exist, cache will miss and the database gets hit again and again.
A Bloom filter can sit before the database:
Request key → Bloom filter
→ definitely not exist: return 404
→ maybe exists: check cache or DB
This protects the database from useless lookups.
False positives
A false positive means:
Bloom filter says “maybe present”
but the item is actually not present.
This is usually okay.
It only causes an extra database lookup.
That is much better than a false negative, which would incorrectly say an existing item does not exist.
Deletion problem
Standard Bloom filters do not support easy deletion.
If your data changes a lot, you may need:
- counting Bloom filter,
- periodic rebuild,
- short-lived Bloom filters,
- or a different data structure.
Common mistakes
- Saying Bloom filter gives exact answers.
- Forgetting false positives.
- Using it as the source of truth.
- Using it when false positives are not acceptable.
- Ignoring deletion.
- Adding it when normal cache or database index is enough.
Final takeaway
Bloom filters are useful when many requests are for things that do not exist.
A strong answer is:
I would use a Bloom filter to quickly reject keys that definitely do not exist. False positives are acceptable because they only cause an extra database lookup. The database remains the source of truth.